Products








Solutions

Retail & eCommerce

Defense

Logistics

Autonomous Vehicles

Robotics

AR/VR

Content & Language

Smart Port Lab

Federal LLMs
Resources
Company
Customers
See all customersGuide to Computer Vision Applications
Understand what computer vision is, how it works, and deep dive into some of the top applications for computer vision by industry.
By Scale Team on January 18th, 2023
Contents
As discussed in our Authoritative Guide to Data Labeling, machine learning (ML) has revolutionized our approach to solving problems in computer vision and natural language processing.
This guide aims to provide an overview of computer vision (CV) applications within the field of machine learning: what it is, how it works, subfields of computer vision, and a breakdown of computer vision use cases by industry.
For decades, people have dreamed of developing machines with the characteristics of human intelligence. An important step in creating this artificial intelligence is giving computers the ability to “see” and understand the world around them.
Computer Vision is a field of artificial intelligence that focuses on developing systems that can process, analyze, and make sense of visual data (images, videos, and other sensor data) similar to the way humans do. From an engineering perspective, computer vision systems not only seek to understand the world around them but aim to automate the tasks the human visual system can perform.
Computer vision is inspired by the way human visual systems and brains work. The computer vision algorithms we use today are based on pattern recognition, training models on massive amounts of visual data. For example, suppose we train a model on a million images of flowers. The system will analyze the million images, identify patterns that apply to all flowers, and at the end will learn to detect a flower given a new image.
A type of deep learning algorithm called a convolutional neural network (CNN) is critical to powering computer vision systems. A CNN consists of an input layer, hidden layers, and an output layer, and these layers are applied to find the patterns described above. CNNs can have tens or even hundreds of hidden layers.
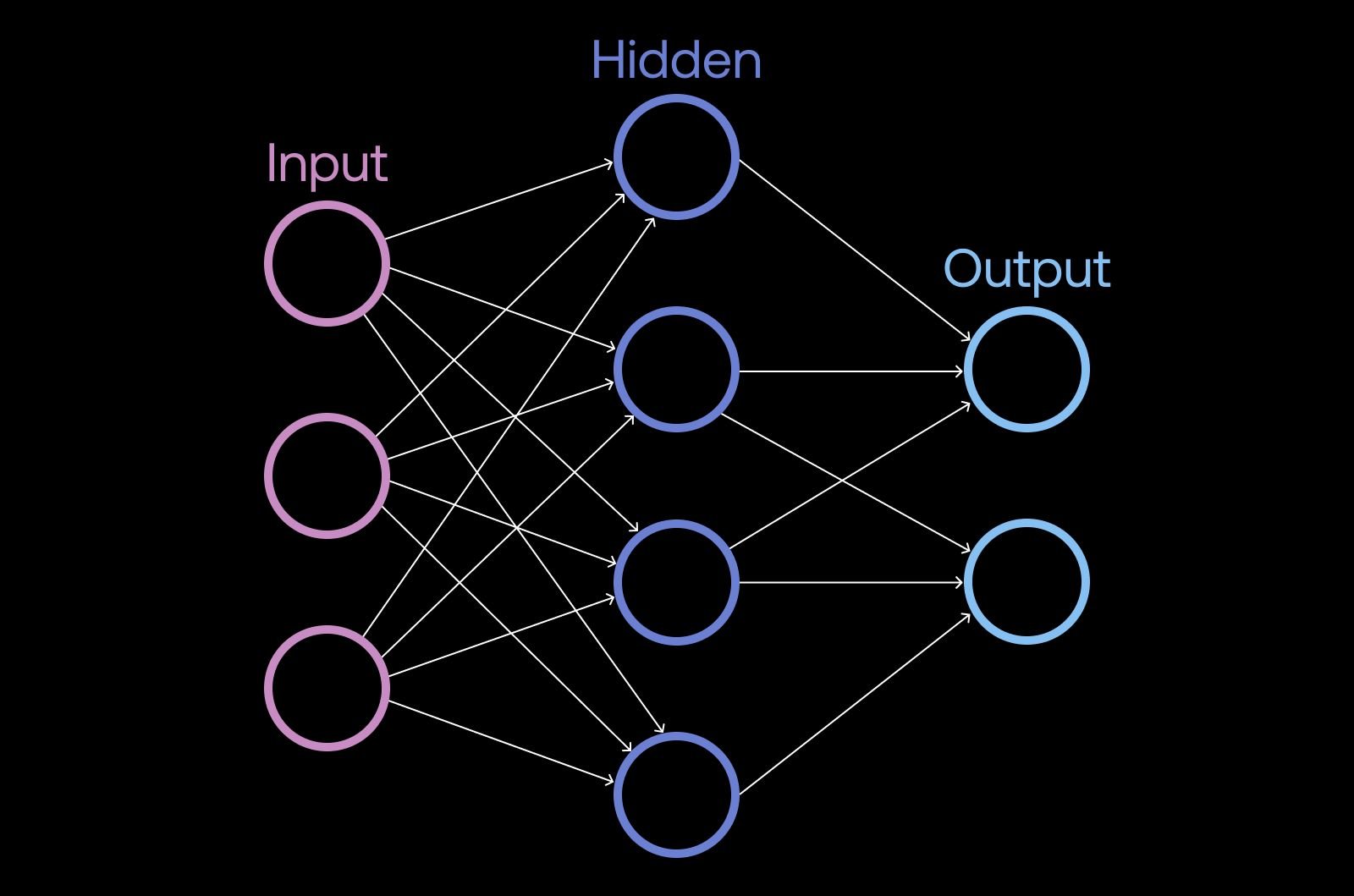
Computer vision applications can be trained on a variety of data types, including images, videos, and other sensor data such as light detection and ranging (LiDAR) data, and radio detection and ranging (RADAR) data. Each data type has its strengths and shortcomings.
Images
Pros:
- Large-scale open-source datasets are available for image data (ImageNet, MS COCO, etc.).
- Cameras are inexpensive if you need to collect data from scratch.
- Images are easier to annotate compared to other data types.
Cons:
- Even the most popular large-scale datasets have known quality issues and gaps that can limit the performance of your models.
- If your use case requires depth perception (e.g. autonomous vehicles or robotics), images alone may not provide the accuracy you need.
- Static images alone are not sufficient to develop object-tracking models.
Videos
Pros:
- Again, cameras are inexpensive if you need to collect data from scratch.
- Enables the development of object tracking or event detection models.
Cons:
- More challenging to annotate compared to images, especially if pixel-level accuracy is required.
LiDAR
What is LiDAR?
LiDAR uses laser light pulses to scan its environment. When the laser pulse reaches an object, the pulse is reflected and returned to the receiver. The time of flight (TOF) is used to generate a three-dimensional distance map of objects in the scene.
Pros:
- LiDAR sensors are more accurate and provide finer resolution data than RADAR.
- Allows for better depth perception when developing computer vision systems.
- LiDAR can also be used to determine the velocity of a moving object in a scene.
Cons:
- Advancements in LiDAR technology have brought down costs in the last few years, but it is still a more costly method of data collection than images or videos.
- Performance degrades in adverse weather conditions such as rain, fog, or snow.
- Calibrating multiple sensors for data collection is a challenge.
- Visualizing and annotating LiDAR data is technically challenging, requires more expertise, and can be expensive.
RADAR
What is RADAR?
RADAR sensors work much like LiDAR sensors but use radio waves to determine the distance, angle, and radial velocity of objects relative to the site instead of a laser.
Pros:
- Radio waves have less absorption compared to the light waves used by LiDAR. Thus, they can work over a relatively long distance, making it ideal for applications like aircraft or ship detection.
- RADAR performs relatively well in adverse weather conditions such as rain, fog, or snow.
- RADAR sensors are generally less expensive than LiDAR sensors.
Cons:
- Less angularly accurate than LiDAR and can lose sight of target objects on a curve.
- Less crisp/accurate images compared to LiDAR.
Advancements in the field of computer vision are driven by robust academic research. In this chapter, we will highlight some of the seminal research papers in the field in chronological order.
ImageNet: A large-scale hierarchical image database
J. Deng, W. Dong, R. Socher, L. -J. Li, Kai Li and Li Fei-Fei, "ImageNet: A large-scale hierarchical image database," 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248-255, doi: 10.1109/CVPR.2009.5206848.
Why it’s important: This paper introduced the Imagenet dataset, which has been the standard in the field of computer vision since 2009.
AlexNet:
A. Krizhevsky, I. Sutskever, and Geoffrey Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems (NIPS), 2012.
Why it’s important: This paper put convolutional neural networks (CNNs) on the map as a solution to solve complicated vision classification tasks.
ResNet:
K. He, X. Zhang, S. Ren, Jian Sun, “Deep Residual Learning for Image Recognition,” arXiv, 2015.
Why it’s important: This paper introduced key ideas to help train significantly deeper CNNs. Deeper CNNs are crucial to improving the performance of computer vision models.
MoCO:
K. He, H. Fan, Y. Wu, S. Xie, and Ross Girshick, “Momentum Contrast for Unsupervised Visual Representation Learning,” 2020 IEEE Conference on Computer Vision and Pattern Recognition, 2019.
Why it’s important: This was the first self-supervised learning paper that was competitive with supervised learning (and sparked the field of contrastive learning).
Vision Transformers:
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and Neil Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” 2021 International Conference on Learning Representations, 2020.
Why it’s important: This paper showed how transformers, which were already dominant in natural language models, could be applied for vision.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis:
B. Mildenhall, P. Srinivasan, M. Tancik, J. Barron, R. Ramamoorthi, and Ren Ng, “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,” 2020 European Conference on Compter Vision, 2020.
Why it’s important: This was a foundational paper for hundreds of papers in the last few years showing how to generate novel views of a 3d scene using a small number of captured images, representing the entire scene implicitly (as opposed to using classical computer graphics representations such as meshes and textures).
Masked Autoencoders:
K. He, X. Chen, S. Xie, Y. Li, P. Dollar, and Ross Girshick, “Masked Autoencoders are Scalable Vision Learners,” arXiv, 2021.
Why it’s important: This paper introduced a new self-supervised learning technique that uses masking ideas that were successful in language. Advantages include that it isn't based on contrastive learning and is efficient.
There are many different subfields or subdomains within computer vision. Some of the most common include: object classification, object detection, object recognition, object tracking, event detection, and pose estimation. In this chapter, we will provide a brief overview as well as an example of these subfields.
Object Classification

With object classification, models are trained to identify the class of a singular object in an image. For example, given an image of an animal, the model would return what animal is identified in the image (e.g. an image of a cat should come back as “cat”).
Object Detection

With object detection, models are trained to identify occurrences of specific objects in a given image or video. For example, given an image of a street scene and an object class of “pedestrian”, the model would return the locations of all pedestrians in the image.
Object Recognition

With object recognition, models are trained to identify all relevant objects in a given image or video. For example, given an image of a street scene, an object recognition model would return the locations of all objects it has been trained to recognize (e.g. pedestrians, cars, buildings, street signs, etc.)
Object Tracking
Object tracking is the task of taking an initial set of object detections, creating unique IDs for each detection, and then tracking each object as it moves around in a video. For example, given a video of a fulfillment center, an object tracking model would first identify a product, tag it, then track it over time as it is moved around the facility.
Event Detection
With event detection, models are trained to determine when a particular event has occurred. For example, given a video of a retail store, an event detection model would flag when a customer has picked up or bagged a product to enable autonomous checkout systems.
Pose Estimation
With pose estimation, models are trained to detect and predict the position and orientation of a person, object, or keypoints in a given scene. For example, given an ego-centric video of a person opening a door, a pose estimation model will detect and predict the position and orientation of the first person’s hands to unlock and open the door.
Depth Estimation
With depth estimation, models are trained to measure the distance of an object relative to a camera or sensor. Depth can be measured either from monocular (single) or stereo (multiple views) images. Depth estimation is critical to enable applications such as autonomous driving, augmented reality, robotics, and more.
Generation
Generative models or diffusion models are a class of machine learning models that can generate new data based on training data. For more on diffusion models, take a look at our Practical Guide to Diffusion Models.
Various industries are developing computer vision applications, from automotive, software & internet, healthcare, retail & eCommerce, robotics, government & public sector, and more. In this chapter, we provide a non-exhaustive list of top computer vision use cases for each industry.
Automotive
Autonomous driving is the automotive industry’s most prominent use case for computer vision. Autonomous driving, however, is not a zero or one proposition. Many automotive manufacturers have been incrementally adding safety and self-driving features to their vehicles that vary in degrees of autonomy and human control. The automotive industry has standardized on a scale from 0 to 5 to describe the levels of autonomy.
Advanced Driver-Assistance Systems (ADAS) are technological features in vehicles designed to increase the safety of driving. ADAS features generally fall under level one or two autonomy in the five levels of autonomous driving. Features such as adaptive cruise control, emergency brake assistance, lane-keeping, and parking assistance are examples of ADAS features.
Autonomous vehicles, or self-driving cars, generally fall under level three, four, or five autonomy. AVs are capable of sensing the environment around them and navigating safely with little to no human input.
Software & Internet
The software and internet industry is pioneering computer vision applications in augmented and virtual reality (AR/VR), content understanding, and more.

Augmented Reality (AR) integrates real-world objects with computer-generated information in the form of text, graphics, audio, and other virtual enhancements. Examples of augmented reality include virtual try-on, Snapchat filters, Pokémon Go, interior decorating apps, 3D exploration of diagnostic imaging, equipment/robotics repair, and more. Virtual Reality (VR), on the other hand, fully immerses a user in a virtual world and obscures the real world.

Content Understanding analyzes, enriches, and categorizes content from social media posts, videos, images, and more. One core application of content understanding is content data enrichment or adding metadata to improve model recommendation rankings. By developing an improved understanding of your content, teams can quickly discover growth areas for better personalization. A second core application is trust and safety, through automated detection of user-generated content that violates a platform's guidelines. Content understanding improves personalization, content recommendation systems, and increased user safety.
Healthcare
The healthcare sector is leveraging computer vision technology to enable healthcare professionals to make better decisions and ultimately improve patient outcomes. The standardization of medical imaging in the Digital Imaging and Communications in Medicine (DICOM) format, as well as the increased use of wearable devices, has led to use cases such as:
- Diagnostics
- Patient monitoring
- Research and development
Retail & eCommerce

Computer vision applications can benefit both shoppers and retailers. CV technology can enhance product discovery and deliver a more seamless shopping experience for customers while enhancing customer engagement, cost savings, operational efficiency, and clicks and conversions for retailers. Use cases include:
- Autonomous Checkout
- Product Matching/Deduplication
- AI-generated product imagery
For more on AI for eCommerce, take a look at our Guide to AI for eCommerce.
Robotics
Agriculture, warehousing and manufacturing, and any other industry that uses robotics has begun leveraging computer vision technology to improve their operations and enhance safety. Uses cases include:
- Inventory sorting and handling
- Defect detection
- Automated harvesting
- Plant disease detection
Government & Public Sector
The US government has troves of geospatial data across a number of sensor types including electro-optical (EO), synthetic aperture radar (SAR), and full motion video (FMV). The amount of geospatial data produced by the US government and commercial satellite vendors is increasing while the amount of analysts power is staying the same. The use of computer vision to process, exploit, and disseminate (PED) this data is essential for the government to utilize the full potential of all available data and derive increasingly meaningful insights about the way our world operates.
Use cases include:
- Assessment of natural disasters and war on infrastructure. Take a look at TIME magazine’s Detecting Destruction best AI invention.
- Intelligence, surveillance, and reconnaissance (ISR)
- Perimeter security
- Environmental monitoring from space
A wide range of industries is developing computer vision applications. The success of computer vision models, however, is highly dependent on the quality of training data models are trained on. From generating, and curating, to annotating data, data pipelines must be set up for success.
To generate data for your models, you can collect data from scratch, leverage existing open-source datasets, or synthetically generate or augment datasets. Once you have generated data, you need to curate that data to identify points of failure and rare edge cases to optimize model performance. From there, you can annotate your data. For a more comprehensive guide on how to annotate data for your machine learning projects, take a look at our Authoritative Guide to Data Annotation.
We hope you found this guide helpful as you think about developing your own CV applications. If you already have data and are ready to get started, check out Scale InstantML, our platform that automatically trains state-of-the-art machine learning models.