Products








Solutions

Retail & eCommerce

Defense

Logistics

Autonomous Vehicles

Robotics

AR/VR

Content & Language

Smart Port Lab

Federal LLMs
Resources
Company
Customers
See all customersData Labeling: The Authoritative Guide
The success of your ML models is dependent on data and label quality. This is the guide you need to ensure you get the highest quality labels possible.
By Jason Liang, Ryan Yao and Dean Shu on August 17th, 2022
Contents

Machine learning has revolutionized our approach to solving problems in computer vision and natural language processing. Powered by enormous amounts of data, machine learning algorithms are incredibly good at learning and detecting patterns in data and making useful predictions, all without being explicitly programmed to do so.
Trained on large amounts of image data, computer models can predict objects with very high accuracy. They can recognize faces, cars, and fruit, all without requiring a human to write software programs explicitly dictating how to identify them.
Similarly, natural language processing models power modern voice assistants and chatbots we interact with daily. Trained on enormous amounts of audio and text data, these models can recognize speech, understand the context of written content, and translate between different languages.
Instead of engineers attempting to hand-code these capabilities into software, machine learning engineers program these models with a large amount of relevant, clean data. Data needs to be labeled to help models make these valuable predictions. Data labeling is one of machine learning's most critical and overlooked activities.
This guide aims to provide a comprehensive reference for data labeling and to share practical best practices derived from Scale's extensive experience in addressing the most significant problems in data labeling.
Data labeling is the activity of assigning context or meaning to data so that machine learning algorithms can learn from the labels to achieve the desired result.
To better understand data labeling, we will first review the types of machine learning and the different types of data to be labeled. Machine learning has three broad categories: supervised, unsupervised, and reinforcement learning. We will go into more detail about each type of machine learning in Why is Data Annotation Important?
Supervised machine learning algorithms leverage large amounts of labeled data to “train” neural networks or models to recognize patterns in the data that are useful for a given application. Data labelers define ground truth annotations to data, and machine learning engineers feed that data into a machine learning algorithm. For example, data labelers will label all cars in a given scene for an autonomous vehicle object recognition model. The machine learning model will then learn to identify patterns across the labeled dataset. These models then make predictions on never before seen data.
Types of Data
Structured vs. Unstructured Data
Structured data is highly organized, such as information in a relational database (RDBMS) or spreadsheet. Customer information, phone numbers, social security numbers, revenue, serial numbers, and product descriptions are structured data.
Unstructured data is data that is not structured via predefined schemas and includes things like images, videos, LiDAR, Radar, some text data, and audio data.
Images
Camera sensors output data initially in raw format and then converted to .png or preferably .jpg files, which are compressed and take up less storage than .png, which is a serious consideration when dealing with the large amounts of data needed to train machine learning models. Image data is also scraped from the internet or collected by 3rd party services. Image data powers many applications, from face recognition to manufacturing defect detection to diagnostic imaging.

Videos
Video data also come from camera sensors in raw format and consist of a series of frames stored as .mp4, .mov, or other video file formats. MP4 is a standard in machine learning applications due to its smaller file size, similar to .jpg for image data. Video data enables applications like autonomous vehicles and fitness apps.
3D Data (LiDAR, Radar)
3D data helps models overcome the lack of depth information from 2D data such as traditional RGB camera sensors, helping machine learning models get a deeper understanding of a scene.
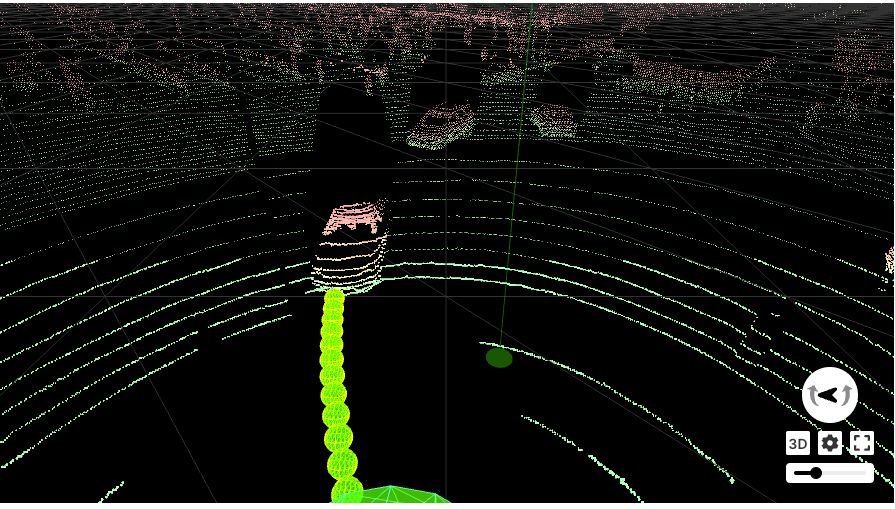
LiDAR (Light Detection and Ranging) is a remote sensing method that uses light to generate precise 3D images of scenes. LiDAR data is stored as point clouds in raw format and the .las file format and are often converted to JSON file format for processing by machine learning applications.
Radar (Radio Detection and Ranging) is a remote sensing method that uses radio waves to determine an object's distance, angle, and radial velocity relative to the radar source.
Audio
Typically stored as .mp3 or .wav file formats, audio data enables speech recognition for your favorite smart assistant and real-time multilingual machine translation.
Text
Text data made of characters representing information, often stored in .txt, .docx, or .html files. Text powers Natural Language Processing (NLP) applications such as virtual assistants when they answer your questions, automated translation, text-to-speech, speech-to-text, and document information extraction.
Machine learning powers revolutionary applications made possible by vast amounts of high-quality data. To better understand the importance of data labeling, it is critical to understand the different types of machine learning: supervised, unsupervised, and reinforcement learning.
Reinforcement Learning leverages algorithms to take actions in an environment to maximize a reward. For instance, Deepmind’s AlphaGo used reinforcement learning to play games against itself to master the game of GO and become the strongest player in history. Reinforcement learning does not rely on labeled data but instead maximizes a reward function to achieve a goal.
Supervised Learning vs. Unsupervised Learning
Supervised learning is behind the most common and powerful machine learning applications, from spam detection to enabling self-driving cars to detect people, cars, and other obstacles. Supervised learning uses a large amount of labeled data to train a model to accurately classify data or predict outcomes.
Unsupervised learning helps analyze and cluster unlabeled data, driving systems like recommendation engines. These models learn from features of the dataset itself, without any labeled data to "teach" the algorithm the expected outputs. A common approach is K-means clustering, which aims to partition n observations into k clusters and assign each observation to the nearest mean.
While there are many fantastic applications for unsupervised learning, supervised learning has driven the most high-impact applications due to its high accuracy and predictive capabilities.
Machine learning practitioners have turned their attention away from model improvement to improving data, coining a new paradigm: data-centric ai. Only a tiny fraction of real-world ML systems are composed of ML code. More high-quality data and accurate data labels are necessary to power better AI. As the methods to create better machine learning models shift to data-centricity, it is essential to understand the entire process of a well-defined data pipeline, from data collection methods to data labeling to data curation.
This guide focuses on the most common types of data labels and the best practices for high quality so that you can get the most out of your data and therefore get the most out of your models.
To create high-quality supervised learning models, you need a large volume of data with high-quality labels. So, how do you label data? First, you will need to determine who will label your data. There are several different approaches to building labeling teams, and each has its benefits, drawbacks, and considerations. Let's first consider whether it is best to involve humans in the labeling process, rely entirely on automated data labeling, or combine the two approaches.
1. Choose Between Humans vs. Machines
Automated Data Labeling
For large datasets consisting of well-known objects, it is possible to automate or partially automate data labeling. Custom Machine Learning models trained to label specific data types will automatically apply labels to the dataset.
Establishing high-quality ground-truth datasets early on, and only then can you leverage automated data labeling. Even with high-quality ground truth, it can be challenging to account for all edge cases and to fully trust automated data labeling to provide the highest quality labels.
Human Only Labeling
Humans are exceptionally skilled at tasks for many modalities we care about for machine learning applications, such as vision and natural language processing. Humans provide higher quality labels than automated data labeling in many domains.
However, human experiences can be subjective to varying degrees and training humans to label the same data consistently is a challenge. Furthermore, humans are significantly slower and can be more expensive than automated labeling for a given task.
Human in the Loop (HITL) Labeling
Human-in-the-loop labeling leverages the highly specialized capabilities of humans to help augment automated data labeling. HITL data labeling can come in the form of automatically labeled data audited by humans or from active tooling that makes labeling more efficient and improves quality. The combination of automated labeling plus human in the loop nearly always outpaces the accuracy and efficiency of either alone.
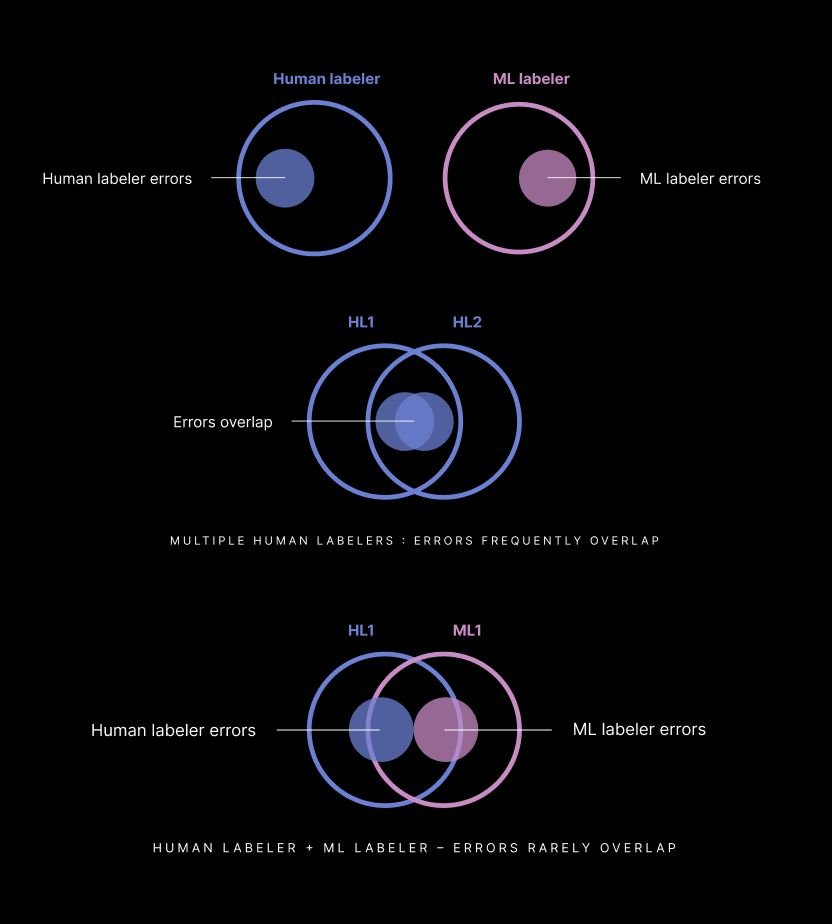
2. Assemble Your Labeling Workforce
If you choose to leverage humans in your data labeling workforce, which we highly recommend, you will need to figure out how to source your labeling workforce. Will you hire an in-house team, convince your friends and family to label your data for free, or scale up to a 3rd Party labeling company? We provide a framework to help you make this decision below.
In-House Teams
Small startups may not have the capital to afford significant investments in data labeling, so they may end up having all the team members, including the CEO, label data themselves. For a small prototype, this approach may work but is not a scalable solution.
Large, well-funded organizations may choose to keep in-house labeling teams to keep control over the entire data pipeline. This approach allows for much control and flexibility, but it is expensive and much work to manage.
Companies with privacy concerns or sensitive data may choose in-house labeling teams. While a perfectly valid approach, this can be difficult to scale.
Pros: Subject matter expertise, tight control over data pipelines
Cons: Expensive, overhead in training and managing labelers
Crowdsourcing
Crowdsourcing platforms provide a quick and easy way to quickly complete a wide array of tasks by a large pool of people. These platforms are fine for labeling data with no privacy concerns, such as open datasets with basic annotations and instructions. However, if more complex labels are needed or sensitive data is involved, the untrained resource pool from crowdsource platforms is a poor choice. Resources found on crowdsourcing platforms are not trained well and lack domain expertise, often leading to poor quality labeling.
Pros: Access to a larger pool of labelers
Cons: Quality is suspect; significant overhead in training and managing labelers
3rd Party Data Labeling Partners
3rd Party data labeling companies provide high-quality data labels efficiently and often have deep machine learning expertise. These companies can act as technical partners to advise you on best practices for the entire machine learning lifecycle, including how to best collect, curate, and label your data. With highly trained resource pools and state-of-the-art automated data labeling workflows and toolsets, these companies offer high-quality labels for a minimal cost.
To achieve extremely high quality (99%+) on a large dataset requires a large workforce (1,000+ data labelers on any given project). Scaling to this volume at high quality is difficult with in-house teams and crowdsourcing platforms. However, these companies can also be expensive and, if they are not acting as a trusted advisor, can convince you to label more data than you may need for a given application.
Pros: Technical expertise, minimal cost, high quality; The top data labeling companies have domain-relevant certifications such as SOC2 and HIPAA.
Cons: Relinquish control of the labeling process; Need a trusted partner with proper certifications to handle sensitive data
3. Select Your Data Labeling Platform
Once you have determined who will label your data, you need to find a data labeling platform. There are many options here, from building in-house, using open source tools, or leveraging commercial labeling platforms.
Open Source Tools
These tools are free to use by anyone, with some limitations for commercial use. These tools are great for learning and developing machine learning and AI, personal projects, or testing early commercial applications of AI. While free, the tradeoff is that these tools are not as scalable or sophisticated as some commercial platforms. Some label types discussed in this guide may not be available in these open-source tools.
The list below is meant to be representative, but not exhaustive so many great open source alternatives may not be included.
- CVAT: Originally developed by Intel, CVAT is a free, open-source web-based data labeling platform. CVAT supports many standard label types, including rectangles, polygons, and cuboids. CVAT is a collaborative tool and is excellent for introductory or smaller projects. However, web users are limited to 500 MB of data and only ten tasks per user, reducing the appeal of the collaboration features on the web version. CVAT is available locally to avoid these data constraints.
- LabelMe: Created by CSAIL, LabelMe is a free, open-source data-labeling platform supporting community collaboration on datasets for computer vision research. You can contribute to other projects by labeling open datasets and label your data by downloading the tool. Labelme is quite limited compared to CVAT, and the web version no longer accepts new accounts.
- Stanford Core NLP: A fully featured NLP labeling and natural language processing platform, Stanford's CoreNLP is a robust open source tool offering Named Entity Recognition (NER), linking, text processing, and more.
In-house Tools
Building in-house tools is an option selected by some large organizations that want tighter control over their ML pipelines. You have direct control over which features to build, support your desired use cases, and address your specific challenges. However, this approach is costly, and these tools will need to be maintained and updated to keep up with the state-of-the-art.
Commercial Platforms
Commercial platforms offer high-quality tooling, dedicated support, and experienced labeling workforces to help you scale and can also provide guidance on best practices for labeling and machine learning. Supporting many customers improves the quality of the platforms for all customers, so you get access to state-of-the-art functionality that you may not see with in-house or open-source labeling platforms.
Scale Studio is the industry-leading commercial platform, providing best-in-class labeling infrastructure to accelerate your team, with labeling tools to support any use case and orchestration to optimize the performance of your workforce. Easily annotate, monitor, and improve the quality of your data.
Whatever annotation platform you use, maximizing the quality of your data labels is critical to getting the most out of your machine learning applications.
The classic computer science axiom "Garbage in Garbage Out" is especially acute in machine learning, as data is the primary input to the learning process. With poor quality data or labels, you will have poor results. We aim to provide you with the most critical quality metrics and discuss best practices to ensure that you are maximizing your labeling quality.
Different Ways to Measure Quality
We cover some of the most critical quality metrics and then discuss best practices to ensure quality in your labeling processes.
Label Accuracy
It is essential to analyze how closely labels follow your instructions and match your expectations. For instance, say you have assigned tasks to data labelers to annotate pedestrians. In your instructions, you have specified labels should include anything carried (i.e., a phone or backpack), but not anything that is pushed or pulled. When you review sample tasks, are the instructions followed, or are strollers (pushed) and luggage (pulled) included in the annotations?
How accurate are labelers on benchmark tasks? These are test tasks to determine overall labeler accuracy and give you more confidence that other labeled data will also be correct. Is labeling consistent across labelers or types of data? If label accuracy is inconsistent across different labelers, this may indicate that your instructions are unclear or that you need to provide more training to your labelers.
Model Performance Improvement
How accurate is your model at its specified task? This output metric is not solely dependent on labeling quality, the quantity and quality of data play a prominent role, but labeling quality is a significant factor to consider.
Let's review some of the most critical model performance metrics.
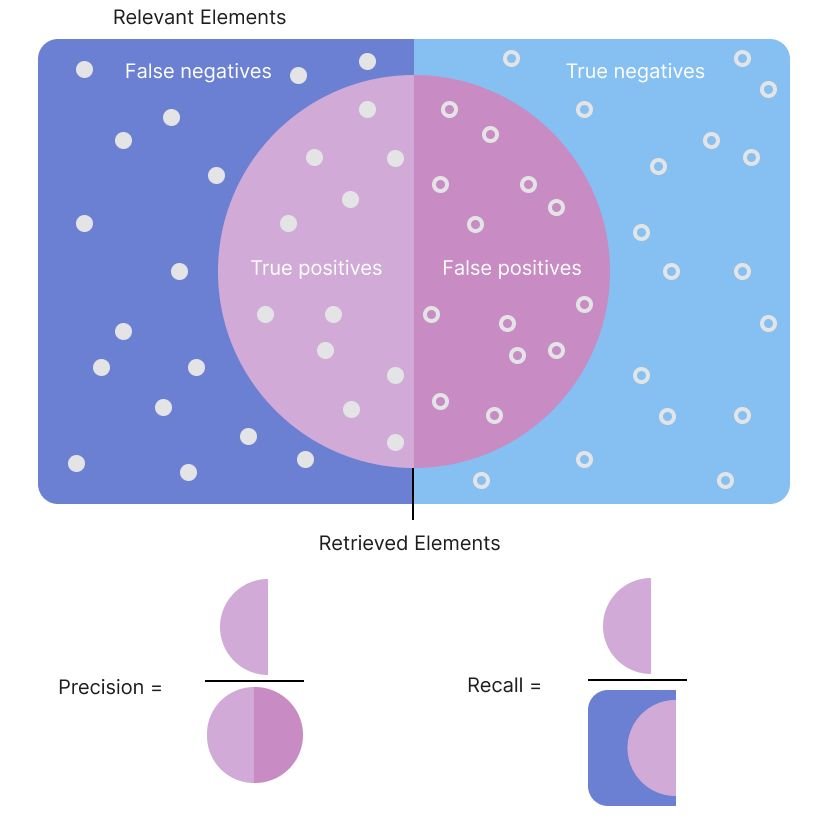
Precision
Precision defines what proportion of positive identifications were correct and is calculated as follows:
Precision = True Positives / True Positives + False Positives
A model that produces no false positives has a recall of 1.0
Recall
Recall defines what proportion of actual positives were identified correctly by the model, and is calculated as follows:
Precision = True Positives / True Positives + False Negatives
A model that produces no false negatives has a recall of 1.0
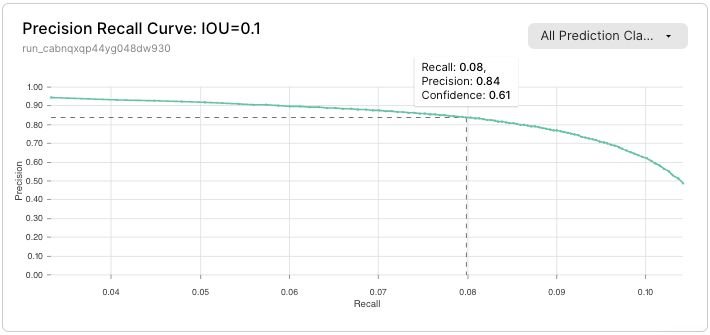
Precision Recall Curve
A model with high recall but low precision returns many results, but many of the predicted labels are incorrect compared to the ground truth labels. On the other hand, a model with high precision but low recall is just the opposite, returning very few results, but most of its predicted labels are correct when compared to the ground truth labels. An ideal model with high precision and high recall will return many results, with all results labeled correctly.
Precision recall curves provide a more nuanced understanding of model performance than any single metric. Precision and recall are a tradeoff; the exact desired values depend on your model and its application.
For instance, for a diagnostic imaging application tasked to detect cancerous tumors, higher recall is desired as it is better to predict that a non-cancerous tumor is cancerous than the alternative of labeling a cancerous tumor as non-cancerous.
Alternatively, applications like SPAM filters require high precision so that important emails are not incorrectly flagged SPAM, even though this may allow more actual SPAM to enter our inbox.
Intersection Over Union (IoU)
An indirect method of confirming label quality in computer vision applications is an evaluation metric called Intersection over Union (IoU).
IoU compares the accuracy of a predicted label over the ground truth label by measuring the ratio of the area of overlap of the predicted label to the area of the union of both the predicted label and the ground truth label.
The closer this ratio is to 1, the better trained the model is.
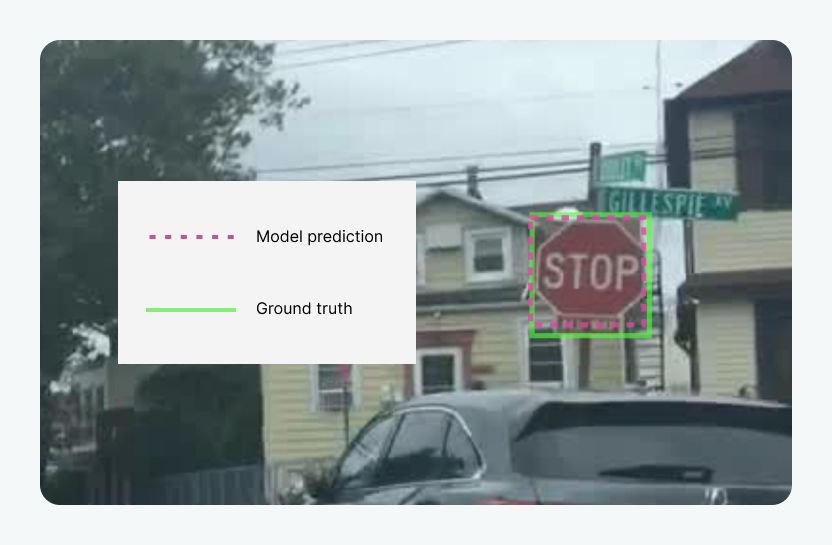
As we discussed earlier, the essential factors for model training are high-quality data and labels. So, IoU is an indirect measure of the quality of data labels. You may have a different threshold of quality that you are focused on depending on the class of object. For instance, if you are building an augmented reality application focused on human interaction, you may need your IoU at 0.95 for identifying human faces but only need an IoU of 0.70 for identifying dogs.
Again, it is critical to remember that other data-related factors can influence IoU, such as bias in the dataset or an insufficient quantity of data.
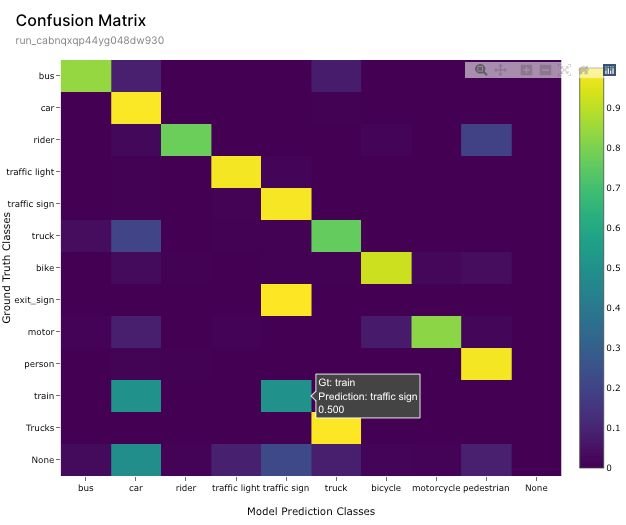
Confusion Matrices
Confusion matrices are a simple but powerful tool to understand class confusion in your model better. A confusion matrix is a grid of classes comparing predicted and actual (ground truth) classifications. By examining the confusion matrix, you can quickly understand misclassifications, such as your model predicting a traffic sign when the ground truth is a train.

Combining these confusions with confidence scores can provide an easy way to prioritize the object confusion, looking at those instances where the model is highly confident in an incorrect prediction. Class confusions are likely due to an issue with incorrect or missing labels or with an inadequate quantity of data containing the traffic sign and train classes.
Best Practices for Achieving High-Quality Labels:
- Collect the best data possible: Your data should be high quality and as consistent as possible while avoiding the bias that may reduce your model's usefulness. Ideally, your data collection pipeline is integrated into your labeling pipeline to increase efficiency and minimize turnaround times.
- Hire the right labelers for the job: Ensure that your labelers speak the right language, are from a specific region, or are familiar with a particular domain. Also, ensure that your labelers are properly incentivized to provide high-quality labels.
- Combine humans and machines: use ML-powered labeling tooling with humans in the loop (HITL) for the highest accuracy labels.
- Provide clear and comprehensive instructions: This will help to ensure that different labelers will label data consistently.
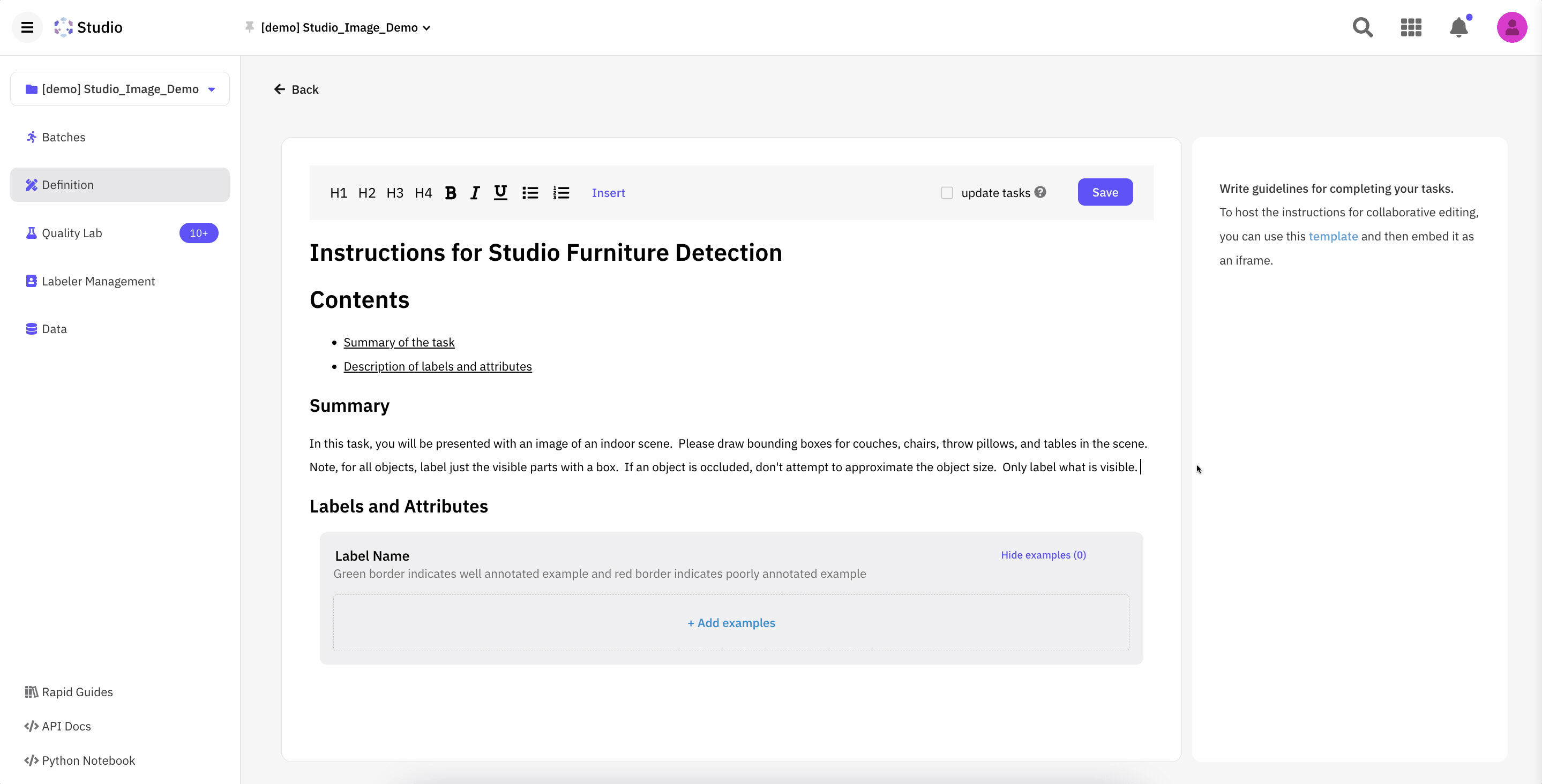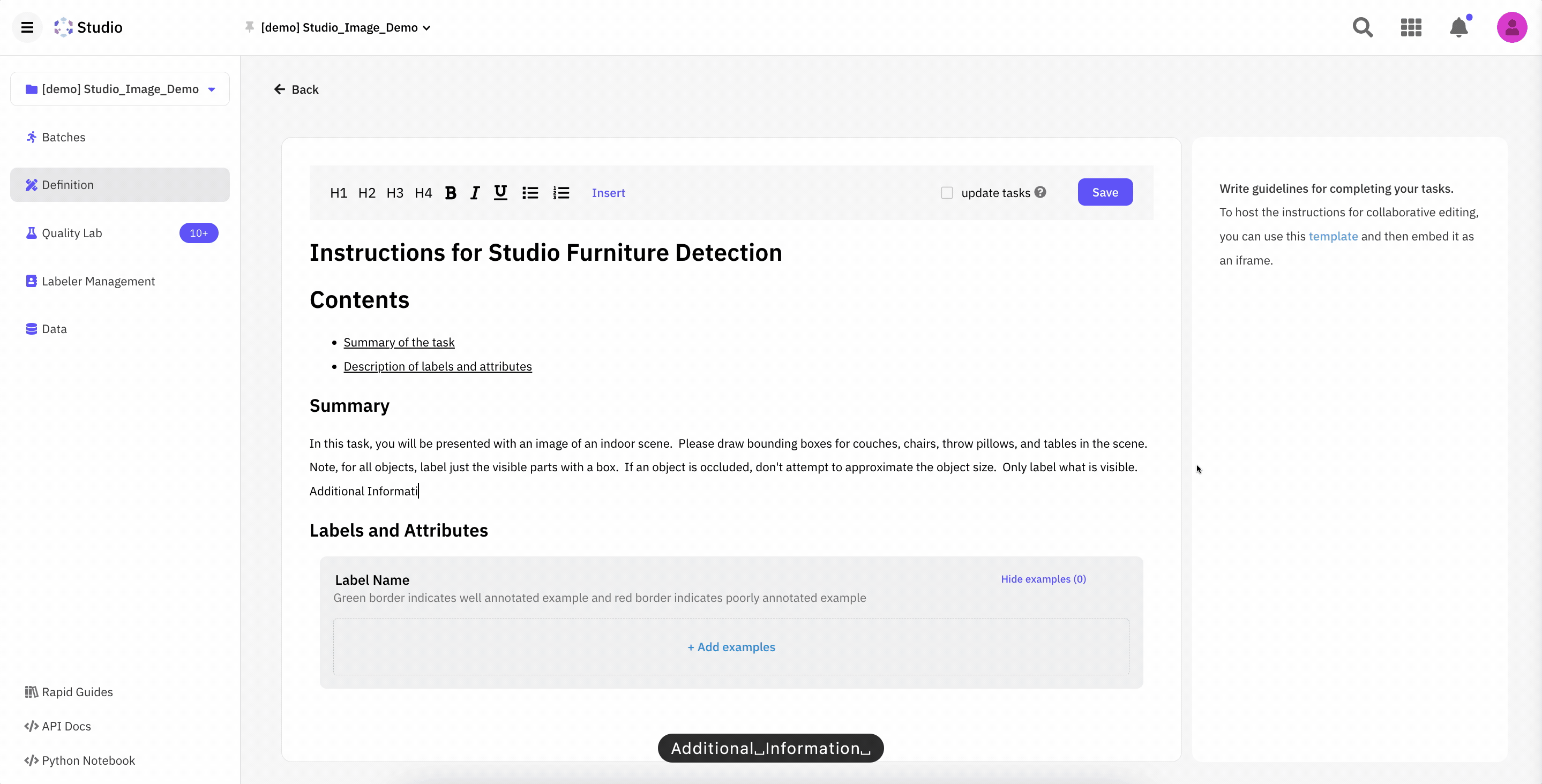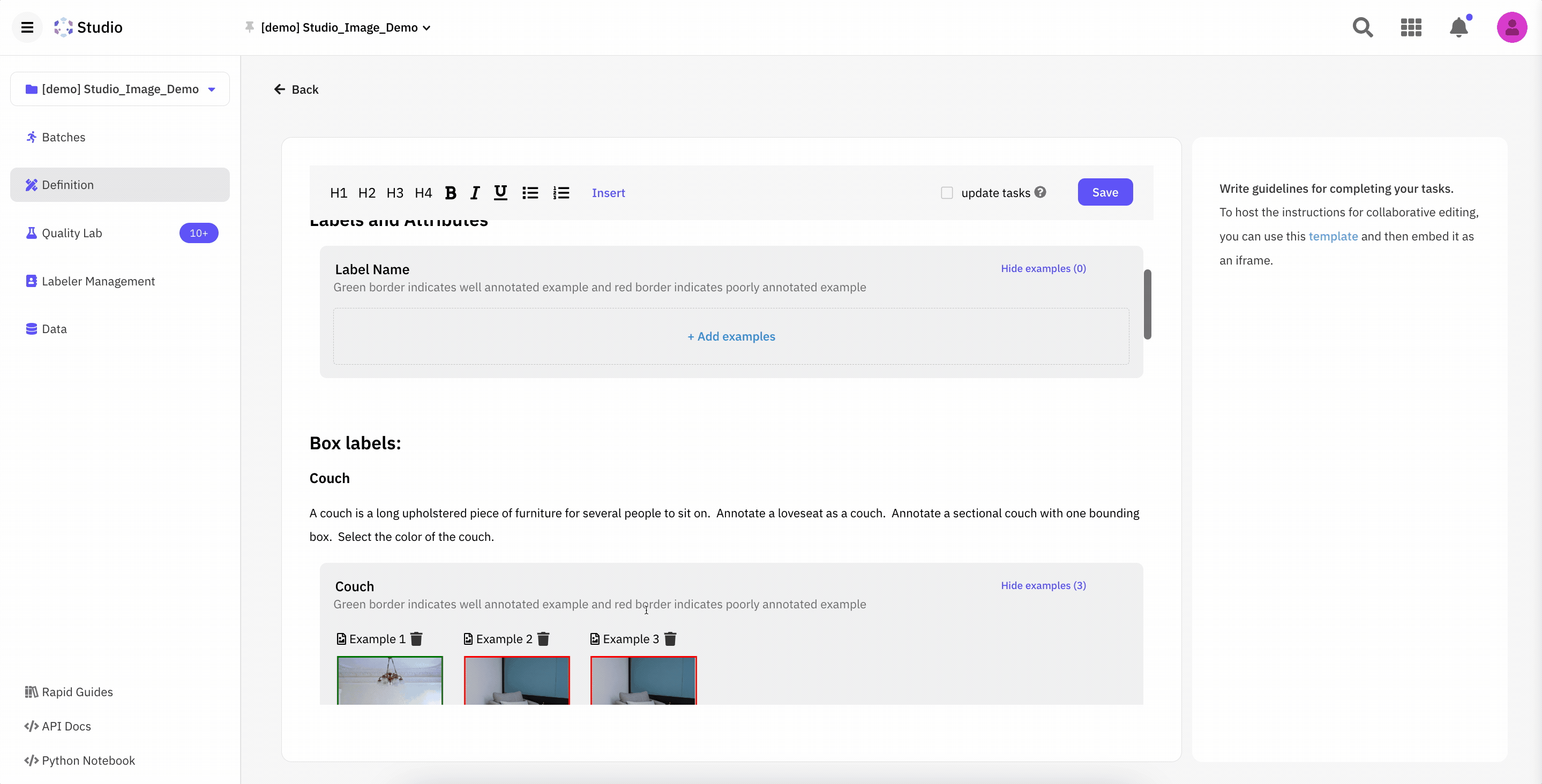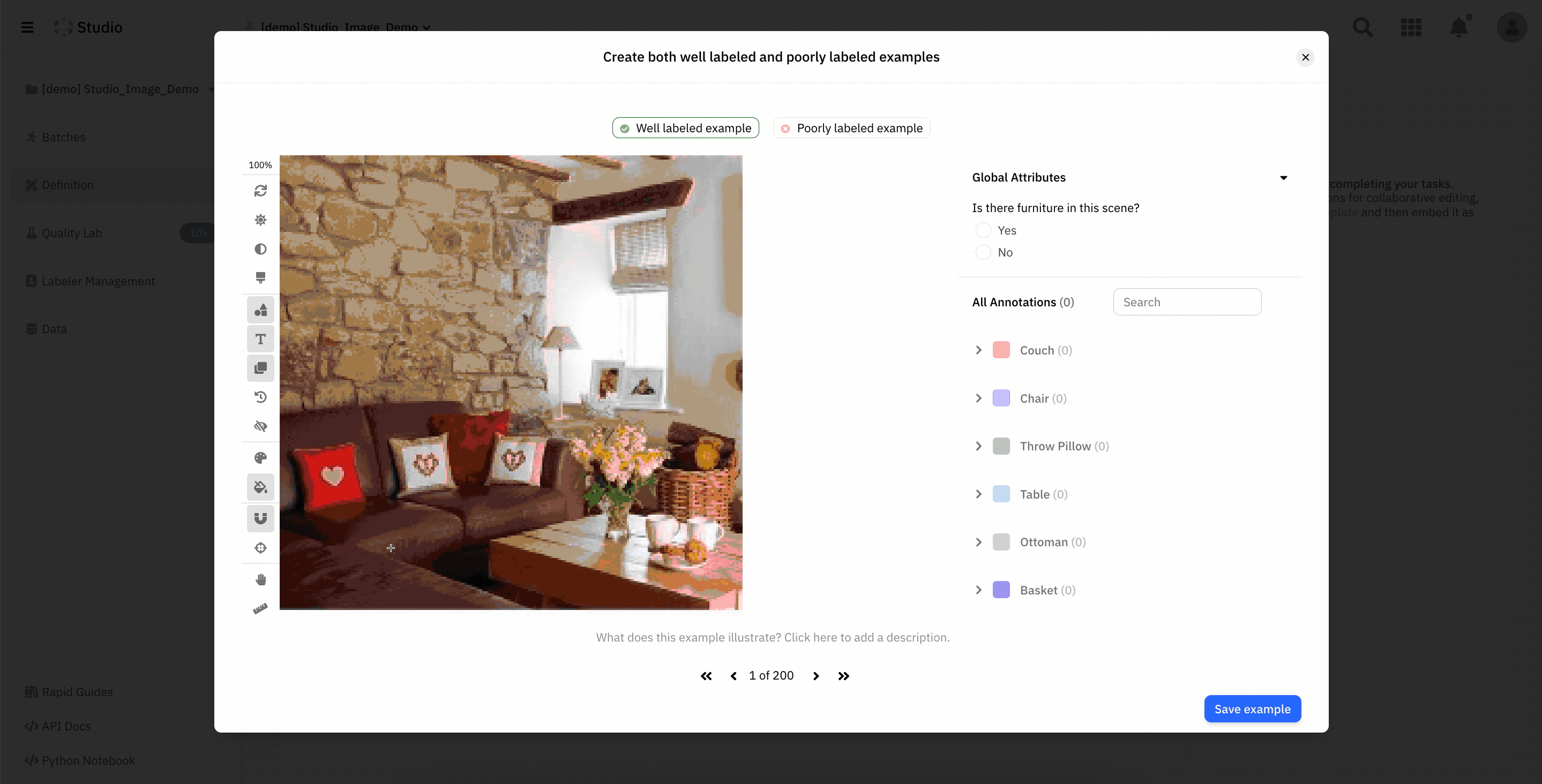
- Curate Your data: As you look to improve your model performance, you will also want to curate your data. Use a data curation tool such as Scale Nucleus to explore your data and identify data that is completely missing labels or improperly labeled. Review your dataset's IoU, ROC curve, and confusion matrix to understand poor model performance better. The best data curation tools will also allow you to visually interact with these charts to visually inspect data related to a specific confusion and even send it to your labeling team to correct. You may also discover that you are missing data, in which case you will need to collect more data to label.
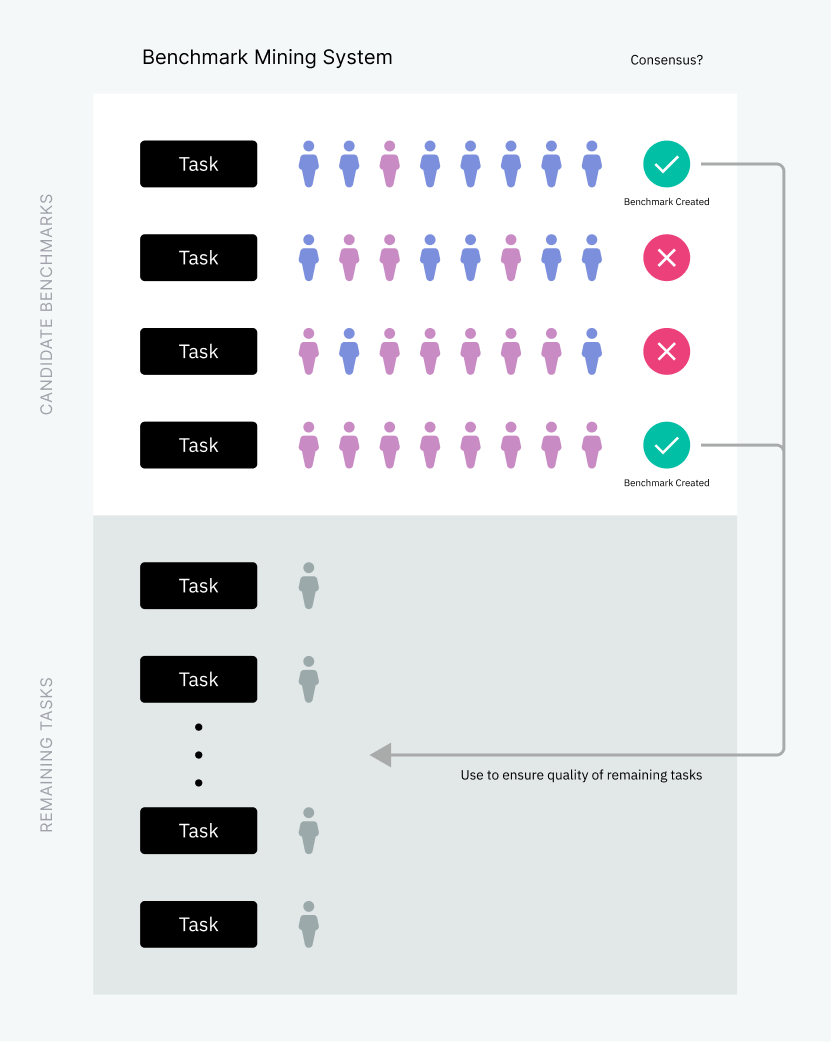
- Benchmark tasks and screening: Collect high-confidence responses to a subset of labeling tasks and use these tasks to estimate the quality of your labelers. Mix these benchmark tasks into other tasks. Use the performance on benchmark tasks to determine if an individual labeler understands your instructions and is capable of providing your desired quality. You can screen labelers who do not pass your benchmark tasks and either retrain them or exclude them from your project.
- Inspect common answers for specific data: Looking at common answers for labels can help you identify trends in labeling errors. If all data labelers are incorrectly classifying a particular object or mislabeling a piece of data, then maybe the issue is not with the labeler but lies somewhere else. Reevaluate your ground truth, instructions, and training processes to ensure that your expectations have been clearly communicated. Once identified, add common mistakes to your instructions to avoid these issues in the future.
- Update your instructions and golden datasets as you encounter edge cases
- Create calibration batches to ensure that your instructions are clear and that quality is high on a small sample of your data before scaling up your labeling tasks.
- Establish a consensus pipeline: Implement a consensus pipeline for classification or text-based tasks with more subjectivity. Use a majority vote or a hierarchical approach based on the experience or proven quality of an individual or group of data labelers.
- Establish layers of review: Establish a hierarchical review structure for computer vision tasks to ensure that the labels are as accurate as possible.
- Randomly sample labeled data for manual auditing: Randomly sample your labeled data and audit it yourself to confirm the quality of the sample. This approach will not guarantee that the entire dataset is labeled accurately but can give you a sense of general performance on labeling tasks.
- Retrain or remove poor annotators: If an annotator's performance does not improve over time and with retraining, then you may need to remove them from your project.
- Measure your model performance: Whether your model performance improves or degrades can often be directly reflected in the quality of your data labels. Use model validation tools such as Scale validate to critically evaluate precision, recall, intersection over union, and any other metrics critical to your model performance.
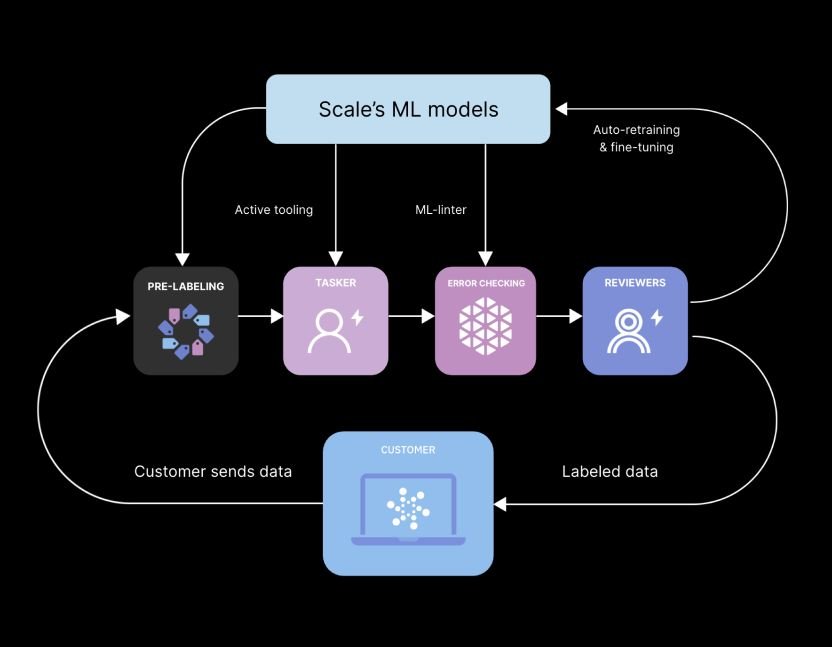
Computer vision is a field in artificial intelligence focused on understanding data from 2D images, videos, or 3D inputs and making predictions or recommendations based on that data. The human vision system is particularly advanced, and humans are very good at computer vision tasks.
In this chapter, we explore the most relevant types of data labeling for computer vision and provide best practices for labeling each type of data.
1. Bounding Box
The most commonly used and simplest data label, bounding boxes are rectangular boxes that identify the position of an object in an image or video
Data labelers draw a rectangular box over an object of interest, such as a car or street sign. This box defines the object's X and Y coordinates.

By "bounding" an object with this type of label, machine learning models have a more precise feature set from which to extract specific object attributes to help them conserve computing resources and more accurately detect objects of a particular type.
Object detection is the process of categorizing objects along with their location in an image. These X and Y coordinates can then be output in a machine-readable format such as JSON.
Typical Bounding Box Applications:
- Autonomous driving and robotics to detect objects such as cars, people, or houses
- Identifying damage or defects in manufactured objects
- Household object detection for augmented reality applications
- Anomaly detection in medical diagnostic imaging
Best Practices:
- Hug the border as tightly as possible. Accurate labels will capture the entire object and match the edges as closely as possible to the object's edges to reduce confusion for your model.
- Avoid item overlap. Due to IoU, bounding boxes work best when there is minimal overlap between objects. If objects overlap significantly, using polygon or segmentation annotations may be better.
- Object size: Smaller objects are better suited for bounding boxes, while larger objects are better suited for instance segmentation. However, annotating tiny objects may require more advanced techniques.
- Avoid Diagonal Lines: Bounding boxes perform poorly with diagonal lines such as walkways, bridges, or train tracks as boxes cannot tightly hug the borders. Polygons and instance segmentation are better approaches in these cases.
2. Classification
Object classification means applying a label to an entire image based on predefined categories, known as classes. Labeling images as containing a particular class such as "Dog," "Dress," or "Car" helps train an ML model to accurately predict objects of the same class when run on new data.
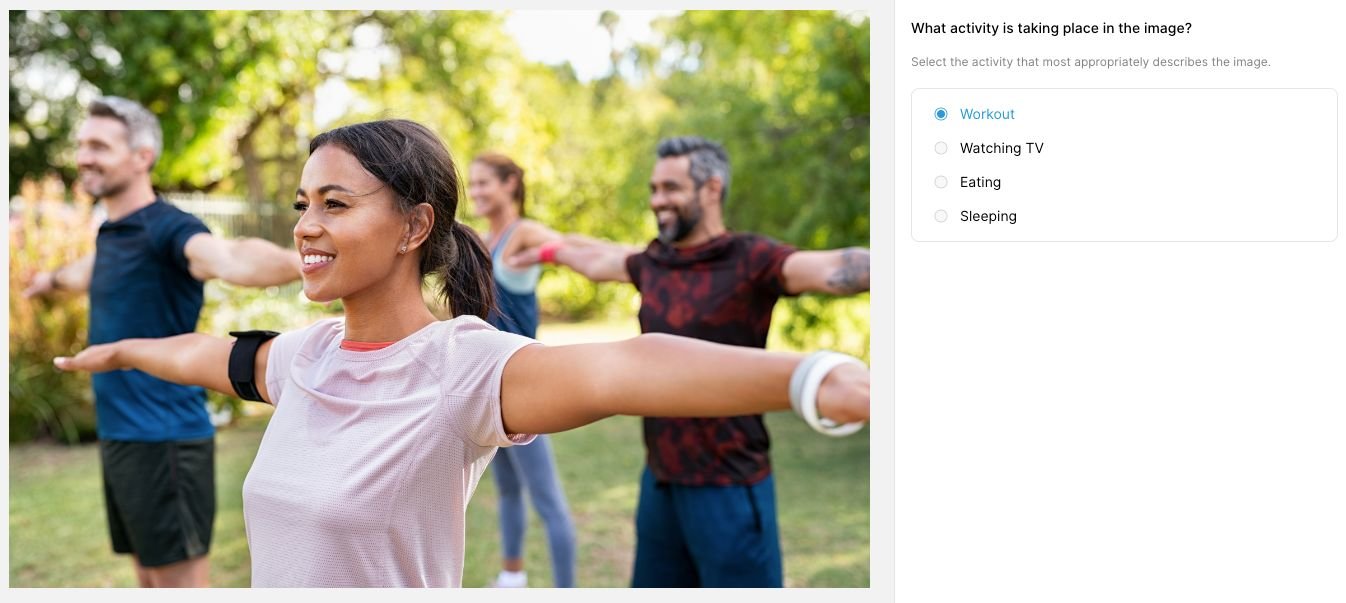
Typical Classification Applications:
- Activity Classification
- Product Categorization
- Image Sentiment Analysis
- Hot Dog vs. Not Hot Dog
Best Practices:
- Create clearly defined, easily understandable categories that are relevant to the dataset.
- Provide sufficient examples and training to your data labelers so that the requirements are clear and ambiguity between classes is minimized.
- Create benchmark tests to ensure label quality.
3. Cuboids
Cuboids are 3-dimensional labels that identify the width, height, and depth of an object, as well as the object's location.
Data labelers draw a cuboid over the object of interest such as a building, car, or household object, which defines the object's X, Y, and Z coordinates. These coordinates are then output in a machine-readable format such as JSON.
Cuboids enable models to precisely understand an object's position in 3D space, which is essential in applications such as autonomous driving, indoor robotics, or 3D room planners. Reducing these objects to geometric primitives also makes understanding an entire scene more manageable and efficient.

Typical Cuboid Applications:
- Develop prediction and planning models for autonomous vehicles using cuboids on pedestrians and cars to determine predicted behavior and intent.
- Indoor objects such as furniture for room planners
- Picking, safety, or defect detection applications in manufacturing facilities
Best Practices:
- Capture the corners and edges accurately. Like bounding boxes, ensure that you capture the entire object in the cuboid while keeping the label as tight to the object as possible.
- Avoid Overlapping labels where possible. Clean, non-overlapping cuboid data annotations will help your model improve object predictions and localizations in 3D space.
- Axis alignment is critical. Ensure that the alignment of your bounding boxes is on the same axis for objects of the same class.
- Keep your camera intrinsics in mind. Applying cuboids without understanding the camera's location will lead to poor prediction results when objects are not in the same position related to the camera in the future. The front face of a "true" cuboid will likely not be a perfect 90-degree rectangle, especially if it isn't facing the camera head-on. Furthermore, the edges of a cuboid parallel to the ground should converge to the horizon, while the top and bottom edges of the right side of the above annotation are parallel.
- Pair 2D Data with 3D Depth Data such as LiDAR.2D images inherently lack depth information, so pairing your 2D data with 3D depth data such as LiDAR will yield the best results for applications dependent on depth accuracy. See the section below on 3D Sensor fusion for more information on this topic.
4. 3D Sensor Fusion
3D sensor fusion refers to the method of combining the data from multiple sensors to accommodate for the weaknesses of each sensor. 2D images alone are not enough for current machine learning models to make sense of entire scenes. Estimating depth from a 2D image is challenging, and occlusion and limited field of view make relying on 2D images tricky. While some approaches to autonomous driving rely solely on cameras, a more robust approach is to overcome the limitations of 2D by supplementing with 3D systems using sensors such as LiDAR and Radar.

LiDAR (Light Detection and Ranging) is a method for determining the distance of objects with a laser to determine the depth of objects in scenes and create 3D representations of the scene.
Radar (Radio detection and ranging) uses radio waves to determine objects' distance, angle, and radial velocity.
This demo provides an interactive 3D sensor fused scene, and the video below gives a high-level overview of a similar scene.
Typical 3D Sensor Fusion Applications
- Autonomous Vehicles
- Geospatial and mapping applications
- Robotics and automation
Best Practices
- Ensure that your data labeling platform is calibrated to your sensor intrinsics (or better yet, ensure that your tooling is sensor agnostic) and supports different lens and sensor types, for example, fisheye and panoramic cameras.
- Look for a data labeling platform that can support large scenes, ideally with support for infinitely long scenes.
- Ensure that object tracking is consistent throughout a scene, even when an object leaves and returns to the scene.
- Include attribute support for understanding correlations between objects, such as truck cabs and trailers.
- Leverage linked instance IDs describing the same object across the 2D and 3D modalities.
5. Ellipses
Ellipses are oval data labels that identify the position of objects in an image. Data labelers draw an ellipse label on an object of interest such as wheels, faces, eyes, or fruit. This annotation defines the object's location in 2D space. The X and Y coordinates of the four extremal vertices of the ellipse can then be output in a machine-readable format such as JSON to fully define the location of the ellipse.

Applications
- Face Detection
- Medical Imaging Diagnosis
- Wheel Detection
Best Practices:
- The data to be labeled should be oval or circular; i.e., it is not helpful to label rectangular boxes with ellipses when a bounding box will yield better results.
- Use ellipses where there would be high overlap for bounding boxes or where objects are tightly clustered or occluded, such as in bunches of fruit. Ellipses can tightly hug the borders of these objects and provide a more targeted geometry to your model.
6. Lines
Lines identify the position of linear objects like roadway markers. Data labelers draw lines over areas of interest, which define the vertices of a line. Labeling images with lines helps to train your model to identify boundaries more accurately. The X and Y coordinates of the vertices of the lines can then be output in JSON.
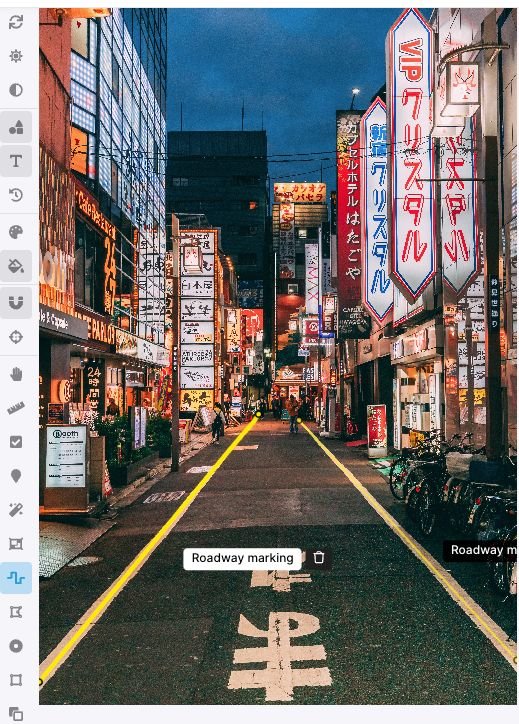
Typical Lines Applications
- Label roadway markers with straight or curved lines for autonomous vehicles
- Horizon lines for AR/VR applications
- Define boundaries for sporting fields
Best Practices
- Label only the lines that matter most to your application.
- Match the lines to the shape of the lines in the image as closely as possible.
- Depending on the use case, it could be important for lines not to intersect.
- Center the line annotation within the line in the image to improve model performance.
7. Points
Points are spatial locations in an image used to define important features of an object. Data labelers place a point on each location of interest, representing that location's X and Y coordinates. These points may be related to each other, such as when annotating a human shoulder, elbow, and wrist to identify the larger moving parts of an arm. These labels help machine learning models more accurately determine pose estimations or detect essential features of an object.

Typical Points Applications
- Pose estimation for fitness or health applications or activity recognition
- facial feature points for face detection
Best Practices
- Label only the points that are most critical to your application. For instance, if you are building a face detection application, focus on labeling salient points on the eyes, nose, mouth, eyebrows, and the outline of the face.
- Group points into structures (hand, face, and skeletal keypoints), and the labeling interface should make it efficient for taskers to visualize the interconnections between points in these structures.
8. Polygons
While bounding boxes are quick and easy for data labelers to draw, they are not precise in mapping to irregular shapes and can leave large gaps around an object. There is a tradeoff between accuracy and efficiency in using bounding boxes and polygons. For many applications, bounding boxes provide sufficient accuracy for a machine learning model with minimal effort. However, some applications require the increased accuracy of polygons at the expense of a more costly and less efficient annotation.
Data labelers draw a polygon shape over an object of interest by clicking on relevant points of the object to complete an entirely connected annotation. These points define the vertices of the polygon. The X and Y coordinates of these vertices are then output in JSON.

Typical Polygons Applications
- Irregular objects such as buildings, vehicles, or trees for autonomous vehicles
- Satellite imagery of houses, pools, industrial facilities, planes, or landmarks
- Fruit detection for agricultural applications
Best Practices
- Objects with holes or those split into multiple polygons due to occlusion (a car behind a tree, for example) require special treatment. Subtract the area of each hole from the object.
- Avoid slight overlaps between polygons that are next to each other.
- Zoom in closely to each object to ensure that you place points close to each object's borders.
- Pay close attention to curved edges, making sure to add more vertices to 'smooth' these edges as much as possible.
- Leverage the Auto Annotate Polygon tool to efficiently label objects. Automatically and quickly generate high-precision polygon annotations by highlighting specific objects of interest with an initial, approximate bounding box.
Follow these steps to achieve success with the Auto Annotate Polygon tool:
- Include all parts of the object of interest.
- Exclude overlapping object instances and other objects as much as possible.
- Keep the bounding box tight to the borders of the object.
- Use click to include/exclude to refine the automatically-generated polygon by instantly performing local edits - include and exclude specific areas of interest.
- Further, refine the polygon by increasing or decreasing vertex density to smooth curved edges.
9. Segmentation
Segmentation labels relate to pixel-wise labels on an image and come in three common types, semantic segmentation, instance segmentation, and panoptic segmentation.
Semantic Segmentation
Label each pixel of an image with a class of what is being represented, such as a car, human, or foliage. Referred to as "dense prediction," this is a time-consuming and tedious process.
With semantic segmentation, you do not distinguish between separate objects of the same class (see instance segmentation for this).

Instance segmentation
Label every pixel of each distinct object of an image. Unlike semantic segmentation, instance segmentation distinguishes between separate objects of the same class (i.e., identifying car 1 as separate from car 2)
Panoptic Segmentation
Panoptic segmentation is the combination of instance segmentation and semantic segmentation. Each point in an image is assigned a class label (semantic segmentation) AND an instance label (instance segmentation). Each instance can represent distinct objects such as cars, people, or regions such as the road or sky. Panoptic segmentation provides more context than instance segmentation and is more detailed than semantic segmentation, making them useful for deeper scene understanding.
Typical Segmentation Applications
- Autonomous Vehicles and Robotics: Identify pedestrians, cars, trees
- Medical Diagnostic imaging: tumors, abscesses in diagnostic imaging
- Clothing: Fashion retail
Best Practices
- Carefully trace the outlines of each shape to ensure that all pixels of each object are labeled.
- Use ML-assisted tooling like the boundary tool to quickly segment borders and objects of interest.
- After segmenting borders, use the flood fill tool to fill in and complete segmentation masks quickly.
- Use active tools like Autosegment to increase the efficiency and accuracy of your labelers.
Explore Coco-Stuff on Nucleus for a large collection of data with segmentation labels!
10. Special considerations for Video Labeling
You can apply many of the same labels to images and videos, but there are some special considerations for video labeling.
Temporal linking of labels
Video annotations add the dimension of time to the data fed to your models, so your model needs a way to understand related objects and labels between frames.
Manually tracking objects and adding labels through many video frames is time and resource intensive. You can leverage several techniques to increase the efficiency and accuracy of temporally linked labels.
- First, you can leverage video Interpolation to interpolate between frames of your video to smooth out the images and labels to make it easier to track labels through the video.
- You should also look for tools that automatically duplicate annotations between frames, minimizing human intervention needed to correct for misaligned labels.
- If you are working with videos, ensure that the tools you are using can handle the storage capacity of the video file and can stitch together hour-long videos so that you retain the same context no matter how long the video.
In videos, objects may leave the camera view and may return at a later time. Leverage tools that enable you to track these objects automatically or make sure to remember to annotate these objects with the same unique ids.
Multimodal
Multimodal machine learning attempts to understand the world from multiple, related modalities such as 2D images, audio, and text.
Combining multiple labeling types such as human keypoints, bounding boxes, and transcribed audio with entity recognition all connected in rich scenes.
Typical Multimodal Applications
- AR/VR full scene understanding Video/GIF/Image (Object Detection + Human Keypoints + Audio Transcription + Entity Recognition)
- Sentiment analysis by combining video gestures and voice data
Best Practices
- Incorporate temporal linking to ensure that models fully understand the entire breadth of each scene.
- Identify which modalities are best suited for your application. For instance, if you are working on sentiment analysis for AR/VR applications, you will want to consider not only 2D video object or human keypoint labels but also audio transcription and entity recognition in addition to sentiment classification so that you have a rich understanding of the entire scene and how the individuals in the scene contribute towards a particular sentiment (i.e., if the person is yelling and gesturing wildly you can determine the sentiment is "upset").
- Include Human in the loop to ensure consistency across modalities. Assign complex scenes to only the most experienced taskers.
Synthetic Data
Synthetic data is digitally-generated data that mimics real-world data. This data is often generated from artists using graphics computer tooling or generated programmatically from models like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), or Neural Radiance Fields (NERFs). Synthetic data includes perfect ground truth labels automatically, without requiring additional human intervention to label the data.

Typical Synthetic Data Applications
- Digital Humans for autonomous vehicles and robotics, particularly in long-tail edge cases such as pedestrians walking on shoulders
- Digital humans for fitness and health applications. Getting enough real-world human pose data is difficult and expensive, whereas synthetic data is relatively easy to generate and cheaper.
- Manufacturing defect detection
Best Practices
- If using a mix of Synthetic and real-world data, ensure that the labels of your real data are as accurate as possible. Synthetic data generates perfectly accurate labels, so any label inaccuracies in your real data will degrade your model's predictive capabilities.
- Leverage synthetic data for data that is difficult to collect due to privacy concerns, rare edge cases, to avoid bias, or prohibitively expensive data collection and labeling methods.
- Integrate synthetic data with your existing data pipelines to maximize your ROI
- Curate your data using best-in-class tools to ensure that you are surfacing the edge cases for which you need more data. Ideally, your dataset curation tool will also integrate into your labeling pipelines.
Labeling text enables natural language processing algorithms to understand, interact with, and generate text for various applications ranging from chatbots to machine translation to product review sentiment analysis.
Like computer vision, there is a wide variety of text label types, and we will cover the most common labels in this guide.
1. Part of Speech Tagging (POS)
Categorizing words in a text (corpus) with a particular part of speech depending on the word's definition and context. This basic tagging enables machine learning models to understand natural language better.
Labeling parts of speech enables chatbots and virtual assistants to have more relevant conversations and better understand the content with which it interacts.

quote source: Scale Zeitgeist, Eric Schmidt, Schmidt Ventures
2. Named Entity Recognition (NER)
Named Entity recognition is similar to speech tagging but focuses on classifying text into predefined categories such as person names, organizations, locations, and time expressions. Linking entities to establish contextual relationships (i.e., Ada Lovelace is the child of Lord and Lady Byron) adds another layer of depth to your model's understanding of the text.
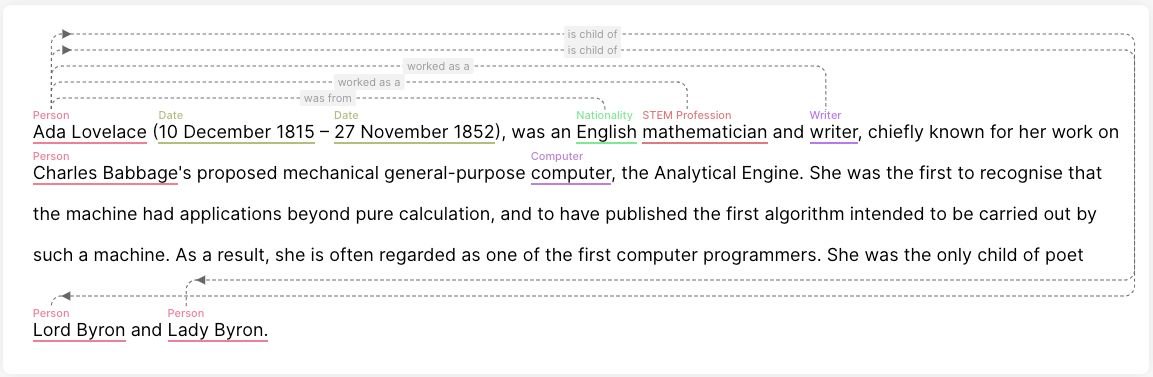
Applications
- Improve search terms
- Ad serving models
- Identify terms in customer interactions (i.e., support threads, chatbots, social media posts) to map to specific topics, brands, etc.
3. Classification
Classify text into predefined categories, such as customer sentiment or chatbots to accurately monitor brand equity, trends, etc.

Applications
- Customer sentiment
- GPT-3 Fine Tuning
- Intent on social media or chatbots
- Active monitoring of brand equity
4. Audio
Transcribe audio data into text for natural language models to make sense of the data. In this case, the text data becomes the label for the audio data. Add further depth to text data with named entity recognition or classification.

5. Best Practices for labeling Text
- Use native speakers, ideally those with a cultural understanding that mirrors the source of the text.
- Provide clear instructions on the parts of speech to be labeled and train your labelers on the task.
- Set up benchmark tasks and build a consensus pipeline to ensure quality and avoid bias.
- Leverage rule-based tagging/heuristics to automatically label known named entities (i.e., "Eiffel Tower") and combine this with humans in the loop to improve efficiency and avoid subtle errors for critical cases.
- Deduplicate data to reduce labeling overhead.
- Leverage native speakers and labelers with relevant cultural experience to your use case to avoid confusion around subtle ambiguities in language. For example, Greeks will associate the color "purple" with sadness. At the same time, those from China and Germany will consider purple emotionally ambivalent, and those from the UK may think purple to be positive.
Hopefully, you have found this guide helpful as you progress in your understanding of machine learning and that you can apply these practical insights to improve your data labeling pipelines. We wanted to share the best practices we learned from providing billions of annotations to some of the largest companies in the world.
As the machine learning market grows, there is an ever greater need for high-quality data and labels. We suggest you take a holistic approach to machine learning, from identifying your core business challenges to collecting and labeling your data.
This guide aims to equip you with the knowledge you need to set up high-quality data annotation pipelines. If you are using your own labeling workforce, check out Scale Studio, which offers a best-in-class annotation infrastructure built by expert annotators. Alternatively, Scale Rapid provides an easy way to offload your data labeling and ramp to production volumes if you need labeling resources. If you have any other questions, please reach out, and we will be happy to help.
1. Scale Studio
Scale's labeling infrastructure, just bring your own labeling workforce.
2. Scale Rapid
Scale up to production workloads with Scale's expert labeling workforce.
Curate your data and identify opportunities to improve annotations.
Dive deeper into the importance of human annotations for deep learning models in this paper written by Scale's own Zeyad Emam, Andrew Kondrich, Sasha Harrison, Felix Lau, Yushi Wang, Aerin Kim, and Elliot Branson.
5. How to Set Up Data Annotation Pipelines
Important factors to consider when setting up you data annotation pipelines, from tooling to automation approaches.