Products








Solutions

Retail & eCommerce

Defense

Logistics

Autonomous Vehicles

Robotics

AR/VR

Content & Language

Smart Port Lab

Federal LLMs
Resources
Company
Customers
See all customersTraining and Building Machine Learning Models
The Foundational Guide
By Scale Team, Barrett Williams and Marwan Mattar on November 1st, 2022
Contents
As we presented in our previous Authoritative Guide to Data Labeling, machine learning (ML) has revolutionized both state of the art research, and the ability of businesses to solve previously challenging or impossible problems in computer vision and natural language processing. Predictive models, trained on vast amounts of data, now have the ability to learn and detect patterns reliably, all without being specifically programmed to execute those tasks.
More broadly, ML models can predict numerical outcomes like temperature or a mechanical failure, recognize cars or retail products, plan better ways to grasp objects, and generate useful and helpful, salient and logical text, all without human involvement. Want to get started training and building models for your business use case? You’ve come to the right place to learn how model training works, and how you too can start building your own ML models!
ML models typically take “high-dimensional” sets of data artifacts as inputs and deliver a classification, a prediction, or some other indicator as an output. These inputs can be text prompts, numerical data streams, images or video, audio, or even three-dimensional point cloud data. The computational process of producing the model output is typically called “inference,” a term adopted from cognitive science. The model is making a “prediction” based on historical patterns.
What distinguishes a ML model from simple heuristics (often conditional statements) or hard-coded feature detectors (yes, face recognition used to depend on detecting a specific configuration of circles and lines!) is a series of “weights,” typically floating point numbers, grouped in “layers,” linked by functions. The system is trained through trial and error, adjusting weights to minimize error (a metric typically referred to as “loss” in the ML world) over time. In nearly all ML models, there are too many of these weights to adjust them manually or selectively; they must be “trained” iteratively and automatically, in order to produce a useful and capable model. Ideally, this model has “learned” on the training examples, and can generalize to new examples it hasn’t seen before in the real world.
Because these weights are iteratively trained, the ML engineer charged with designing the system in most cases can only speculate or hypothesize about the contribution of each individual weight to the final model. Instead, she must tweak and tune the dataset, model architecture, and hyperparameters. In a way, the ML engineer “steers the ship” rather than micromanaging the finest details of the model. The goal after many rounds of training and evaluation (known as “epochs”) is to induce the process to reduce model error or loss (as we mentioned above) closer and closer to zero. Typically when a model “converges,” loss decreases to a global minimum where it often stabilizes. At this point, the model is deemed “as good as it’s going to get,” in the sense that further training is unlikely to yield any performance improvements.
Sometimes it’s possible to detect that a model’s performance metrics have stabilized and engage a technique known as “early stopping.” It doesn’t make sense to spend additional time and compute spend on additional training that doesn’t meaningfully improve the model. At this stage, you can evaluate your model to see if it’s ready for production or not. Real-world user testing is often helpful to determine if you’re “ready” to launch the product that encapsulates your model, or you need to continue tweaking, adding more data, and re-training. In most applications, externalities will cause model failures or drift, requiring a continued process of maintenance and improvement of your model.
Divvying up your data
In order to train a model that can properly “generalize” to data it has never seen before, it’s helpful to train the model on most on 50-90% of available data, while leaving 5-20% out in a “validation” set to tune hyperparameters, and then also save 5-20% to actually test model performance. It’s important not to “taint” or “contaminate” the training set with data the model will later be tested on, because if there’s identical training assets between train and test, the model can “memorize” the result, thereby overfitting on that example, compromising its ability to generalize, which is typically an important attribute of nearly every successful ML model. Some researchers refer to the test set (that the model has never seen before) as the “hold-out” or “held out” set of data. You can think of this as the “final exam” for the model, which the model shouldn’t have seen verbatim before exam day, even if it has seen similar examples in the metaphorical problem sets (to which it has checked against the answer key) during prior training.
Tabular data
If you’re simply interested in computer vision, or some of the more sophisticated and recent data types that ML models can tackle, skip ahead to the Computer Vision section. That said, working with tabular data is helpful to understand how we arrived at deep learning and convolutional neural networks for more complex data types. Let’s begin with this simpler data type.
Tabular data typically consists of rows and columns. Columns are often different data types that correspond to each row entry, which might be a timestamp, a person, a transaction, or some other granular entry. Collectively, these columns can serve as “features” that help the model reliably predict an outcome. Or, as a data scientist, you can choose to multiply, subtract, or otherwise combine multiple columns and train the model on those combinations. For tabular data, there are a wide variety of possible models one can apply, to predict a label, a score, or any other (often synthesized) metric based on the inputs. Often, it’s helpful to eliminate columns that are “co-linear,” although some models are designed to deprioritize columns that are effectively redundant in terms of determining a predictive outcome.
Tabular data continues the paradigm of separating training and test data, so that the model doesn’t “memorize” the training data and overfit—regurgitate examples it has seen, but fumble its response to ones it hasn’t. It even enables you to dynamically shift the sections of the table that you’ll use (best practice is to randomize the split, or randomize the table first) such that test, train, and evaluation sets are all in windows that can be slid or swapped across your dataset. This is known as cross-fold validation, or n-folds validation, where n represents the number of times the table is “folded” to divvy up your training and test sets in different portions of the table.

Source: Wikipedia
A final point about tabular data that we’ll revisit in the computer vision section is that data often has to be scaled to a usable range. This might mean scaling a range of values from 1 to 1000000 into a floating point number such that the range is between 0 and 1.0 or -1.0 and 1.0. Machine Learning engineers often need to experiment with different types of scaling (perhaps logarithmic is also useful for some datasets) in order for the model to reach its most robust state—generating the most accurate predictions possible.
Text
No discussion of machine learning would be complete without discussing text. Large language models have stolen the show in recent years, and they generally function to serve two roles:
- Translate languages from one to another (even a language with only minimal examples on the internet)
- Predict the next section of text—this might be a synthesized verse of Rumi or Shakespeare, a typical response to a common IT support request, or even an impressively cogent response to a specific question
In addition to deep and large models, there are a number of other techniques that can be applied to text, often in conjunction with large language models, including unsupervised techniques like clustering, principal components analysis (PCA), and latent dirichlet allocation (LDA). Since these aren’t technically “deep learning” or “supervised learning” approaches, feel free to explore them on your own! They may prove useful in conjunction with a model trained on labeled text data.
For any textual modeling approach, it’s also important to consider “tokenization.” This involves splitting words in the training text into useful chunks, which might be individual words, full sentences, stems, or even syllables. Although it’s now quite old, the Python-based Natural Language Toolkit (NLTK) includes Treebank and Snowball tokenizers, which have become industry standard. SpaCy and Gensim also include more modern tokenizers, and even PyTorch, a cutting-edge, actively developed Python ML library includes its own tokenizers.
But back to large language models: it’s typically helpful to train language models on very large corpuses. Generally speaking, since text data requires much less storage than high resolution imagery, you can either train models on massive text datasets (generally known as “corpuses,” or if you’re a morbid scholar of Latin, maybe you can write corpora) such as the entire Shakespeare canon, every Wikipedia article ever written, every line of public code on GitHub, every public-domain book available on Project Gutenberg, or if you’d rather writing a scraping tool, as much of the textual internet as you can save on a storage device quickly accessible by the system on which you plan to train your model.
Large language models (LLMs) can be “re-trained” or “fine tuned” on text data specific to your use case. These might be common questions and high quality responses paired with each question, or simply a large set of text common to the same company or author, from which the model can predict the next n words in the document. (In Natural Language, every body of text is considered a “document”!) Similarly, translation models can start with a previously trained, generic LLM and be fine-tuned to support the input-output use case that translation from one language to another requires.
Images
Images are one of the earliest data types on which researchers trained truly “deep” neural networks, both in the past decade, and in the 1990s. Compared to tabular data, and in some cases even audio, uncompressed images take up a lot of storage. Image size not only scales with the width and height (in pixels) but also in color depth. (For example, do you want to store color information or only brightness values? In how many bits? And how many channels?) Handwritten digit detection is one of the simpler images to detect as it requires only comparing binary pixel values at relatively low resolution. In the 1990s, most neural networks were laboriously trained on large sequential computers to adjust the model weights so that handwriting recognition (in the form of Pitney Bowes’ postal code detector in conjunction with Yann LeCun’s LeNet network), and MNIST’s DIGITS dataset is still considered a useful baseline computer vision dataset for proving a minimal baseline of viability for a new model architecture.
More broadly speaking, images include digital photographs as most folks know and love them, captured on digital cameras or smartphones. Images typically include 3 channels, one each for red, blue, and green. Brightness is encoded usually in the form of 8- or 10-bit sequences for each color channel. Some ML model layers will simply look at brightness (in the form of a grayscale image) while others may learn their “features” from specific color channels while ignoring patterns in other channels.
Many models are trained on CIFAR (smaller, 10 or 24 classes of labels), ImageNet (larger, 1000 label classes), or Microsoft’s COCO dataset (very large, includes per-pixel labels). These models, once reaching a reasonable level of accuracy, can be re-trained or fine-tuned on data specific to a use case: for example, breeds of dogs and cats, or more practically, vehicle types.
Video
Video is simply the combination of audio and a sequence of images. Individual frames can be used as training data, or even the “delta” or difference between one frame and the next. (Sometimes this is expressed as a series of motion vectors representing a lower-resolution overlay on top of the image.) Generally speaking, individual video frames can be processed with a model just like an individual image frame, with the only difference that adjacent frames can leverage the fact that there might be overlap between a detected object in one frame and its (sometimes) nearby location in the next frame. Contextual clues can assist per-frame computer vision, including speech recognition or sound detection from the paired audio track.
Audio
Sound waves, digitized in binary representation, are useful not just for playback and mixing, but also for speech recognition and sentiment analysis. Audio files are often compressed, perhaps with OGG, AAC, or MP3 codecs, but they typically all decompress to 8, 16, or 24 bit amplitude values, with sample rates anywhere between 8 kHz and 192 kHz (typically at multiples-of-2 increments). Voice recordings generally require less quality or bit-depth to capture, even for accurate recognition, and (relatively) convincing synthesis. While traditional speech to text services used Hidden Markov Models (HMMs), long short-term memory networks (LSTMs) have since stolen the spotlight for speech recognition. They typically power voice-based assistants you might use or be familiar with, such as Alexa, Google Assistant, Siri, and Cortana. Training text to speech and speech to text models typically takes much more compute than training computer vision models, though there is work ongoing to reduce barriers to entry for these applications. As with many other use cases, transformers have proven valuable in increasing the accuracy and noise-robustness of speech-to-text applications. While digital assistants like Siri, Alexa, and Google Assistant demonstrate this progress, OpenAI’s Whisper also demonstrates the extent to which these algorithms are robust to mumbling, background interference, and other obstacles. Whisper is unique in that it can be called via API rather than used in a consumer-oriented end product.
3D Point Clouds
Point clouds encode the position of any number of points, in three-dimensional Cartesian (or perhaps at the sensor output, polar) space. What might at first look like just a jumble of dots on screen typically can be “spun” on an arbitrary axis with the user’s mouse, revealing that the arrangement of points is actually three-dimensional. Often, this data is captured by laser range-finders that spin radially, mounted on the roof of a moving vehicle. Sometimes a “structured light” infrared camera or “time-of-flight” camera can capture similar data (at higher point density, usually) for indoor scenes. You may be familiar with similar cameras thanks to the Wii game console remote controller (Wiimote), or the Xbox Kinect camera. In both scenarios, sufficiently detailed “point clouds” can be captured to perform object recognition on the object in frame for the camera or sensor.

Multimodal Data
It turns out the unreasonable effectiveness of deep learning doesn’t mandate that you only train on one data type at a time. In fact, it’s possible to ingest and train your model on images and audio to produce text, or even train on a multi-camera input in which all cameras capturing an object at a single point in time are combined into a single frame. While this might be confusing as training data to a human, certain deep neural networks perform well on mixed input types, often treated as one large (or “long”) input vector. Similarly, the model can be trained on pairs of mismatched data types, such as text prompts and image outputs.
Support Vector Machines (SVMs)
SVMs are one of the more elementary forms of machine learning. They are typically used as classifiers (yes, it’s OK to think of “hot dog” versus “not hot dog,” or preferably cat versus dog as labels here), and while no longer the state of the art for computer vision, they are still useful for handling “non-linear” forms of classification, or classification that can’t be handled with a simple linear or logistic regression. (think nearest neighbor, slope finding on a chart of points, etc.) You can learn more about SVMs on their documentation page at the scikit-learn website. We’ll continue to use scikit-learn as a reference for non-state-of-the-art models, because their documentation and examples are arguably the most robust available. And scikit-learn (discussed in greater depth below) is a great tool for managing your dataset in Python, and then proving that simpler, cheaper-to-train, or computationally less complex models aren’t suitable for your use case. (You can also use these simpler models as baselines against which you can compare your deep neural nets trained on Scale infrastructure!)

Random Forest Classifiers
Random Forest Classifiers have an amazing knack of finding just the right answer, whether you’re trying to model tabular data with lots of collinearities or you need a solution that’s not computationally complex. The “forest” of trees is dictated by how different buckets of your data impact the output result. Random Forest Classifiers can find non-linear boundaries between adjacent classes in a cluster map, but they typically don’t track the boundary perfectly. You can learn more about Random Forest Classifiers, again, over at scikit-learn’s documentation site.

Source: Wikipedia
Gradient-Boosted Trees
Gradient-boosting is another technique/modification applied to decision trees. These models can also handle co-linearities, as well as a number of hyperparameters that can limit overfitting. (Memorizing the training set so that training occurs with high accuracy, but does not extend to the held-out test set.) XGBoost is the framework that took Kaggle by storm, and LightGBM and Catboost also have a strong following for models of this class. Finally, this level of model complexity begins to depart from some of the models in scikit-learn that derive from simpler regressions, as hyperparameter count increases. (Basically there are now more ways in which you can tune your model, increasing complexity.) You can read all about how XGBoost works here. While there are some techniques to attribute model outputs to specific columns or “features” on the input side, with Shapley values perhaps, XGBoost models certainly demonstrate that not every ML model is truly “explainable.” As you might guess, explainability is challenged by model complexity, so as we dive deeper into complex neural networks, you can begin to think of them more as “black boxes.” Not every step of your model will necessarily be explainable, nor will it necessarily be useful to hypothesize why the values of each layer in your model ended up the way they did, after training has completed.
Feedforward Neural Networks
These are the simplest form of neural networks in that they accept a fixed input length object and provide classification as an output. If the model extends beyond an input layer and an output layer (each with its own set of weights), it might have intermediate layers that are termed “hidden.” The feedforward aspect means that there are no backwards links to earlier layers: each node in the graph is connected in a forward fashion from input to output.
Recurrent Neural Networks
The next evolution in neural networks was to make them “recurrent.” That means that nodes closer to the output can conditionally link back to nodes in earlier layers—those closer to the input in the inference or classification pipeline. This back-linking means that some neural networks can be “unrolled” into simpler feedforward networks, whereas some connections mean they cannot. The variable complexity resulting from the classification taking loops or not means that inference time can vary from one classification run to the next, but these models can perform inference on inputs of varying lengths. (Thus not requiring the “fitting” mentioned above in the tabular data section.)
Convolutional Neural Networks
Convolutional Neural Nets have now been practically useful for roughly 10 years, including on higher resolution color imagery, in large part thanks to graphics processors (GPUs). There’s much to discuss with CNNs, so let’s start with the name. Neural nets imply a graph architecture that mimics the interconnected neurons of the brain. While organic neurons are very much analog devices, they do send signals with electricity much like silicon-based computers. The human vision system is massively parallel, so it makes sense that a parallel computing architecture like a GPU is properly suited to compute the training updates for a vision model, and even perform inference (detection or classification, for example) with the trained model. Finally, the word “convolution” refers to a mathematical technique that includes both multiplication and addition, which we’ll describe in greater detail in a later section on model layers.
Long Short-Term Memory Networks (LSTMs)
If you’ve been following along thus far, you might notice that most models you’ve encountered up until this point have no notion of “memory” from one classification to the next. Every “inference” performed at runtime is entirely dependent on the model, with no influence from any other inference that came before it. That’s where “Long Short Term Networks” or LSTMs come in. These networks have a “gate” at each node in the network that allows the weights to remain unchanged. This can sometimes mitigate the “vanishing gradient” problem in RNNs, in which all weights in a layer might “vanish” to 0 if a change of the weight is mandatory in every epoch (a single step-wise update of all of the weights in the model based on the output loss function) of the training run. Because weights can persist for many epochs, this is similar to physiological “short term memory,” encoded in the synaptic connections in the human brain: some are weakened or strengthened or left alone as time passes. Let’s turn back to applications from theory, though: some earlier influential LSTMs became renowned for their ability to detect cat faces in large YouTube-derived datasets like YouTube-8M. Eventually the model could operate in reverse, recalling the rough outline of a cat face, given the “cat” label as an input.
Q-Learning
Q-Learning is a “model-free” approach to learning, using reinforcement with an “objective function” to guide updates to the layers in the network. DeepMind instituted this process in their famous competition against world champion Lee Sedol at the game of Go. Q-Learning has since shown to be incredibly successful at learning other historically significant Atari Games, as well as RPG strategy games like WarCraft and StarCraft.

—OpenAI and MuJoCo, from OpenAI Gym
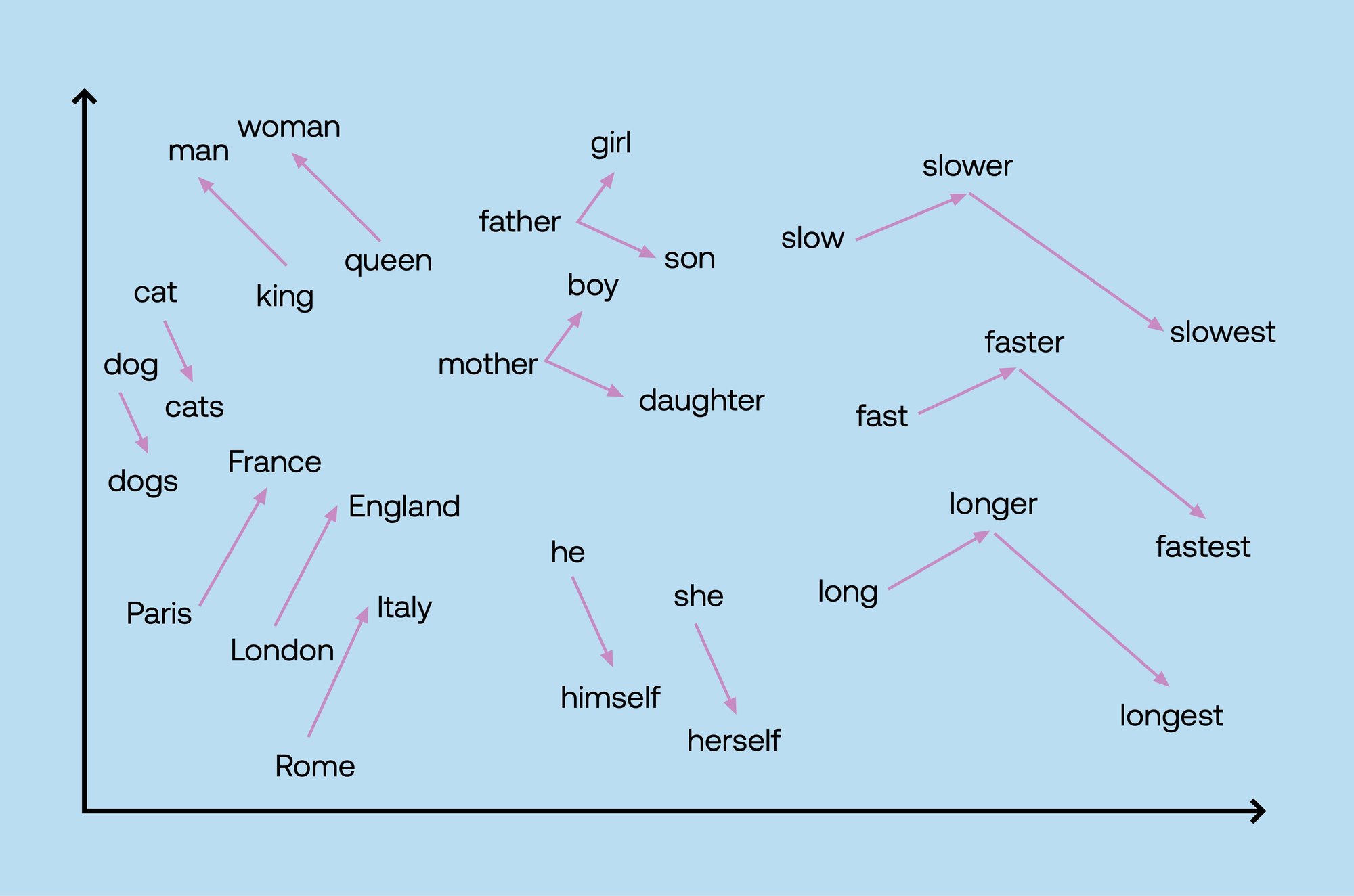
Word2Vec
Thus far, we haven’t spent much time or words on text models, so it’s time to begin with Word2Vec. Word2Vec is a series of models that matches word pairs with cosine similarity scores, so that they can be productively mapped in vector space. Word2Vec can produce a distributed representation of words or a continuous “bag-of-words,” or a continuous “skip-gram.” CBOW is faster, while “skip-gram” seems to handle infrequent words better. You can learn more about word2vec in the documentation for the industry-standard gensim Python package. If you’re looking to synthesize biological sequences like DNA, RNA, or even proteins, word2vec also proves useful in these scenarios: it handles sequences of biological and molecular data in the same way it does words.

Transformers
After LSTMs and RNNs reigned as the state of the art for natural language processing for several years, in 2017, a group of researchers at Google Brain formulated a set of multi-head attention layers that began to perform unreasonably well on translation workloads. These “attention units” typically consist of a scaled dot product. The only drawback to this architecture was that training on large datasets and verifying performance on long input strings during training was both computationally intensive and time-consuming. Attention(Q,K,V), or attention as a function of the matrices Q, K, and V, is equivalent to the softmax(QKT/sqrt(dk))*V. Modifications to this approach are typically focused on reducing the computational complexity from O(N2) to O(N ln N) with Reformers, or to O(N) with ETC or BigBird, where N is the input sequence length. The larger, in the case of BERT, “teacher” model is typically a product of self-supervised learning, starting with unsupervised pre-training on large Internet corpuses, followed by supervised fine-tuning. Common tasks that transformers can reliably perform include:
- Paraphrasing
- Question Answering
- Reading Comprehension
- Sentiment Analysis
- Next Sentence Prediction/Synthesis
As the authors of this model class named their 2017 research paper, “Attention Is All You Need.” This title was prescient, as transformers are now a lower-case category, and have influenced vision systems as well (known as Vision Transformers, or ViT for short), CLIP, DALL-E, GPT, BLOOM, and other highly influential models. Next, we’ll jump into a series of specific and canonically influential models—you’ll find the transformer-based models at the end of the list that follows.
AlexNet (historical)
AlexNet was the model that demonstrated that compute power and convolutional neural nets could scale to classify as many as 1000 different classes in Stanford’s canonical ImageNet dataset (and corresponding image classification challenge). The model consisted of a series of activation layers, hidden layers, ReLUs, and some “pooling” layers, all of which we’ll describe in a later section. It was the first widely reproduced model to be trained on graphics processors (GPUs), two NVIDIA GTX 580s, to be specific. Nearly every successor model past this point was also trained on GPUs. AlexNet won the 2012 N(eur)IPS ImageNet challenge, and it would become the inspiration for many successor state-of-the-art networks like ResNet, RetinaNet, and EfficientDet. Whereas predecessor neural networks such as Yann LeCun’s LeNet could perform fairly reliable classification into 10 classes (mapping to the 10 decimal digits), AlexNet could classify images into any of 1000 different classes, complete with confidence scores.
Original paper here and Papers with Code.
ResNet
Residual Networks—ResNet for short—encompass a series of image classifiers of varying depth. (Depth, here, roughly scaling with classification accuracy and also compute time.) Often, while training networks like AlexNet, the model won’t converge reliably. This “exploding/vanishing” (“vanishing” was explained above, while “exploding” means the floating point value rapidly increases to the maximum range of the data type) gradient problem becomes more challenging as the ML engineer adds more layers or blocks to the model. Compared to previous “VGG” nets of comparable accuracy, designating certain layers as residual functions drastically reduces complexity, enabling models up to 152 layers deep that still have reasonable performance in terms of inference time and memory usage. In 2015, ResNet set the standard by winning 1st place in ImageNet and COCO competitions, for detection, localization, and segmentation.
Original paper here on arXiv and Papers with Code.
Single Shot MultiBox Detector (SSD)
Single Shot MultiBox Detector (SSD) was published at NeurIPS in 2015 by Wei Li, a member of Facebook AI Research. Written in Caffe, it provided an efficient way for neural networks to also identify bounding boxes for objects, and dynamically update the object detection bounding boxes dynamically. While AlexNet proved the value of image classification to the market, SSD paved the way for increasingly accurate forms of object detection, even at high frame rates, as can be found on a webcam (60 frames per second or “FPS”), autonomous vehicle, or security camera (often lower, perhaps 24 FPS).
Original paper here on arXiv and Papers with Code.
Faster R-CNN and Mask R-CNN
It’s helpful to have bounding boxes (rectangles, usually) to identify objects in an image, but sometimes even greater levels of detail can be useful. Happily, it’s possible to train models on datasets that include images and matching per-pixel labels. Faster R-CNN (published by Matterport, a residential 3D scanning company) and its spiritual successor, Mask R-CNN are notable and iterative models that generate robust pixel-wise predictions in a relatively short amount of time. These models can be particularly useful for robotics applications such as picking objects out of boxes, or re-arranging objects in a scene. Mask R-CNN was published under the name “Detectron” on GitHub by Facebook AI Research. We’ll cover its successor, Detectron2, below.
Original papers here and here on arXiv and here and here on Papers with Code.
You Only Look Once (YOLO) and YOLOv3
Along the lines of SSD, mentioned above, Joseph Redmon at University of Washington decided to eschew the then-burgeoning TensorFlow framework in favor of hand-coding another “single shot” object detector with the goal of making it run extremely fast on C and CUDA (GPU programming language) code alone. His model architecture lives on in the form of Ultralytics, a business organized around deploying YOLOv5, now in PyTorch, models (currently) to customers. YOLO is an architecture that has stood the test of time and is somewhat relevant today, pushing the barriers of high-quality and high-speed object detection.
Original papers here and here on arXiv and here and here Papers with Code.

Inception v3 (2015), RetinaNet (2017) and EfficientDet (2020)
In the decade that has passed since Alex Krizhevsky published AlexNet at the University of Toronto, every few years a new model would win in the annual ImageNet and MSCOCO challenges. Today, it may seem as though high-accuracy, high-speed object detection is a “solved” problem, but of course there is always room to discover smaller, simpler models that might perform better on speed, quality, or some other metric. There have been some steps forward in the state-of-the-art for objective detection based on “neural architecture search,” or using a model to select different configurations and sizes and types of layers. Yet, today’s best models learn from those experiments but no longer explicitly search for better model configurations with an independent ML model.
Original papers for Inception v3, RetinaNet, and EfficientDet are available on arXiv. You can find Inception v3, RetinaNet, and EfficientDet on Papers with Code as well.

Mingxing Tan et al., 2020, Comparative Performance of Several Models
U-Net
Deep neural networks found a very effective use case in the field of diabetic retinopathy (eye scans to diagnose diabetes), and thus a number of research efforts sprung up to pursue semantic segmentation models for other forms of radiology, including medical scans like Computerized Tomography (CT scans). U-Net, also originally implemented in Caffe, used a somewhat novel mirror-image architecture with high dimensional inputs and outputs corresponding to the per-pixel labels, for both cell detection and anomaly labeling. U-Net is still relevant today, as it has influenced more modern models like Detectron2 and even Stable Diffusion for both semantic segmentation and image generation.
Original paper here on Springer and Papers with Code.
Detectron2
In 2019, Facebook Research moved the bar up another notch for both semantic segmentation and object detection with the same paper, Panoptic-DeepLab, freely available in the Detectron2 repository on GitHub. Today, Detectron2 serves as a state-of-the-art low latency, high accuracy gold standard for semantic segmentation and object detection. It seems that every couple years or so the state of the art is solidly surpassed, sometimes at the expense of compute resources, but soon enough these models are compressed or simplified to aid in deployment and training. Perhaps in another couple years, compute and memory requirements will be drastically reduced, or an indisputably higher quality benchmark will be established.
Original paper here on arXiv and Papers with Code.
GPT-3
Switching over to Natural Language use cases, the industry focused much on translation, with popular services like Google Translate developing markedly better performance thanks to switching from word-by-word translations through dictionary lookups to using transformer models to predict the next word of the translated output, using the entire source phrase as an input. Outside of Google, the next watershed moment for Natural Language computation came with OpenAI’s GPT. Trained on Common Crawl, Wikipedia, Books and web text-based datasets, the final trained model size includes 175 billion parameters, a decisively large model for its time, and still an impressive size as of writing. Just as BERT (a predecessor transformer-based language model) inspired more efficient, smaller derivatives before it, since GPT-3’s release in 2020, the smaller InstructGPT model, released in 2022, has shown a greater ability to respond to directive prompts instructing the model to do something specific, all while including fewer weights. One important ingredient in this mix is RLHF, or Reinforcement Learning from Human Feedback, which seems to enable enhanced performance despite a smaller model size. A modified version of GPT-3 is trained on public Python code available in GitHub, known as Codex, and is deployed as “GitHub Copilot” in Microsoft’s open source (VS) Code integrated development environment (IDE).
Original paper here on arXiv and GitHub.

BLOOM
BLOOM is a new model intended to serve a similar purpose to GPT-3, as a large language model for text generation, except the entire model and training dataset are all open-source and freely accessible, unlike GPT-3, which is only shared by OpenAI and Microsoft as a paid API. The trained BLOOM model (full size) is 176 billion parameters, meaning to train it from scratch required significant compute expense, so the model was trained on the IDRIS supercomputer near Paris, as part of a BigScience workshop organized in conjunction with government and academic research entities in France. BLOOM is arguably more accessible for model fine-tuning for specific applications because the training data and model code are all fully open source.
Code and context available on the HuggingFace blog.
The following section includes references to paper covered in our guide to Diffusion Models.
DALL·E 2
Released in 2022, DALL·E 2 impressed the industry with its uncanny ability to generate plausible, aesthetically pleasing imagery from text prompts. Similar to GPT-3 and running LSTM classification inference in reverse, DALL·E 2 is trained on a large dataset of imagery and its corresponding description text, scraped from the internet. Faces are removed, and a combination of models and human feedback are used to remove explicit or unsafe content, in order to decrease the likelihood that the model generates unsafe outputs. DALL·E 2 is available as an API, and is used in Microsoft’s Designer and Image Creator apps.
The DALL·E 2 paper is available on the OpenAI website. Unfortunately no model code is available at this time.
Stable Diffusion
In contrast to OpenAI’s approach with DALL·E 2, a group of startup founders including Stability.ai’s Emad Mostaque and the members of RunwayML decided to publish a functionally equivalent model and dataset to OpenAI’s API. Termed Stable Diffusion, it builds on a technique developed a year earlier at LMU in Munich, using a series of noising and denoising steps to generate images from text prompts, or from a source image. It is also possible to use a technique called “outpainting,” to ask the model to expand the canvas in a specified direction, running the model additional times to synthesize tiles that expand the final image. The model architecture embeds U-net as a central component, and can be run on consumer graphics cards. (More than 10GB VRAM is preferred.) Unlike DALL·E 2, since Stable Diffusion can be run locally on the user’s workstation, harmful text prompts are not filtered. Thus it is mainly the responsibility of the user to only use the model for productive rather than harmful purposes.
Code and context available on the HuggingFace model card page.
Input Image (or other input matrix p × q × r)
Typically images are scaled or padded to fixed input dimensions, 256 × 256 pixels, for example. Modern networks can learn from color values as well as brightness, so models can focus on learning features from color data as well as brightness. Color cues might be essential to classify one bird species from another, or classify one type of manufacturing defect from another. If an input image to a model at inference time is too large to scale down to 256 × 256 without losing significant information, the image can be iteratively scanned, one row at a time, with a sliding classification box that strobes the image from left to right, top to bottom. The distance between one scanning window’s location and the next one is known as the model’s “stride.” Meanwhile, on the training side, much research has been devoted to identifying the best ways to crop, scale, and pad images with “blank” or “zero” pixels such that the model remains robust at inference time.
Convolutional Layer
A convolution is a signal processing technique and mathematical function that takes two signals as inputs and outputs the integral of the product of those two functions. The second input function is flipped across the y-axis and moved along the baseline of the function to calculate the output signal over time. Convolutions are a common function for switching a signal between the time domain and frequency domain, or vice versa.
Sigmoid
With a linear activation function, a neural network can only learn a linear boundary between one class and the other. Many real-world problems have non-linear boundaries between the classes, and thus they need a non-linear activation function.
ReLU (Rectification Linear Unit)
A ReLU layer is computationally much simpler than a sigmoid as it simply sets all negative number inputs to zero and scales all positive inputs linearly. It turns out that ReLU is a fast, functional replacement for the much more expensive Sigmoid function to connect layers.
Pooling layer
This layer down-samples features found in various regions of the image, making the output “invariant” to minor translations of objects or features found in the image. While it is possible to adjust the “stride” of a convolution (the distance between the centers of successive convolution “windows”), it is more common to use a pooling layer to “summarize” the features discovered in each region of an image.
Softmax
This is typically the last activation function of a neural network, used to normalize the output to a probability distribution over predicted output classes. It basically translates the intermediate values of the neural network back into the intended output labels or values. In a way, the softmax function is the reverse of any input-side transformation the training and test data may undergo (downsampling to 256×256 resolution, or conversion from an integer to a floating point number between 0 and 1, for example).
Scikit-learn
Scikit-learn is a Swiss Army knife of frameworks in that it supports everything from linear regression to convolutional neural networks. ML engineers typically don’t use it for bleeding edge research or production systems, except for maybe its data loaders. That said, it is incredibly useful for establishing utilities for splitting training from evaluation and test data, and loading a number of base datasets. It also can be used for baseline (simpler) models, such as Support Vector Machines (SVMs) and Histogram of Gradients (HOGs) to use as sanity checks, comparing algorithmically and computationally simpler models to their more sophisticated, modern counterparts.
XGBoost
XGBoost is a framework that allows the simple training of gradient-boosted trees, which has also proven its value across a wide range of tabular use cases on Kaggle, an online data science competition platform. In many scenarios, before training an LSTM to make a prediction, it’s often helpful to try an Xgboost model first, to disprove the hypothesis that a simpler model might possibly do the job equally well, if not better.
Caffe (historical)
Yangqing Jia wrote the Caffe framework while he was a PhD student at UC Berkeley with the intent of giving developers access to machine learning primitives that he wrote in C++ and CUDA (GPU computation language), with a Python interface. The framework was primarily useful for image classification and image segmentation with CNNs, RCNNs, LSTMS, and fully connected networks. After hiring Jia, Facebook announced Caffe2, supporting RNNs for the first time, and then soon merged the codebase into PyTorch (covered two sections later).
TensorFlow
Originally launched in 2015, TensorFlow quickly became the standard machine learning framework for training and deploying complex ML systems, including with GPU support for both training and inference. While TensorFlow is still in use in many production systems, it has seen decreased popularity in the research community. In 2019, Google launched TensorFlow 2.0, merging Keras’ high-level capabilities into the framework. TensorBoard, a training and inference stats and visualization tool also saw preliminary support for PyTorch, a rival, more research-oriented framework.
PyTorch
Roughly a year after TensorFlow’s release, Facebook (now Meta) released PyTorch, a port of NYU’s Torch library from the relatively obscure Lua programming language over to Python, hoping for mainstream adoption. Since its release, PyTorch has seen consistent growth in the research community. As a baseline, it supports scientific computing in a manner similar to NumPy, but accelerated on GPUs. Generally speaking, it offers more flexibility to update a model’s graph during training, or even inference. For some researchers the ability to perform a graph update is invaluable. The PyTorch team (in conjunction with FAIR, the Facebook AI Research group) also launched ONNX with Microsoft, an open source model definition standard, so that models could be ported easily from one framework to another. In September 2022, Meta (formerly Facebook) announced that PyTorch development would be orchestrated by its own newly created PyTorch Foundation, a subsidiary of the Linux Foundation.
Keras (non-TensorFlow support is now only historical)
In 2015, around the same time as TensorFlow’s release, ML researcher François Chollet released Keras, in order to provide an “opinionated” library that helps novices get started with just a few lines of code, and experts deploy best-practices prefab model elements without having to concern themselves with the details. Initially, Keras supported multiple back-ends in the form of TensorFlow, Theano, and Microsoft’s Cognitive Toolkit (CNTK). After Chollet joined Google a few years later, Keras was integrated into the version 2.0 release of TensorFlow, although its primitives can still be called via its standalone Python library. Chollet still maintains the library with the goal of automating as many “standard” parts of ML training and serving as possible.
Chainer (historical)
Initially released in 2015 by the team at Japan’s Preferred Networks, Chainer was a Python-native framework especially useful in robotics. While TensorFlow had previously set the industry standard, using the “define then run” modality, Chainer pioneered the “define-by-run” approach, which meant that every run of a model could redefine its architecture, rather than relying on a separate static model definition. This approach is similar to that of PyTorch, and ultimately Chainer was re-written in PyTorch to adapt to a framework that was independently growing in popularity and matched some of Chainer’s founding design principles.
YOLOv5
Although we have already addressed YOLO above as a model class, there have been significant updates to this class, with YOLOv5 serving as Ultralytics’ PyTorch rewrite of the classic model. Ultimately, the rewrite uses 25% of the memory of the original and is designed for production applications. YOLO’s continued support and development is a testament to the efficiency of its original design, and successive iterations of YOLO continue to provide competitive, high-performance semantic segmentation and object detection, even though the original model consciously chose to avoid using industry-standard frameworks like TensorFlow and PyTorch.
HuggingFace Transformers
The world of machine learning frameworks and libraries is no stranger to higher-level abstractions, with Keras serving as the original example of this approach. A wider ranging, and more recent attempt at building a higher level abstraction library for dataset ingest, training, and inference, Transformers provides easy few-line access in Python to numerous APIs in Natural Language, Computer Vision, audio, and multimodal models. Transformers also offers cross-compatibility with PyTorch, TensorFlow, and Jax. It is accessible through a number of sample Colab notebooks as well as on HuggingFace’s own Spaces compute platform.
When choosing metrics for training your model, you might start with loss, or default to accuracy, but it’s also important to make sure that your metrics are business-aligned. This might mean that you care more about certain classification or prediction scenarios than others. In effect, you will want to use your model to match your business priorities, rather than distract or detract from them.
Minimizing loss
As you train the model and use a function to continuously update the weights in various layers, the goal is always to “minimize loss” in the form of error. Thus, if loss is continuously decreasing, your model is converging towards a state in which it might make useful classifications or predictions. Loss is the metric the model attempts to optimize as it iteratively updates the individual weights—the end user of a model might care more about other, derivative metrics like accuracy, precision, and recall, which we’ll discuss next.
Maximizing accuracy
Every few “epochs” or so of updating the weights in the layers of your neural network, you’ll evaluate the model’s accuracy to ensure that it’s improved rather than degraded. Typically accuracy is evaluated on the test set and the training set to make sure that performance isn’t maximized on one but minimized on the other (this is known as “overfitting” where the model performs well on training data, but can’t generalize to the test data it’s never seen before).
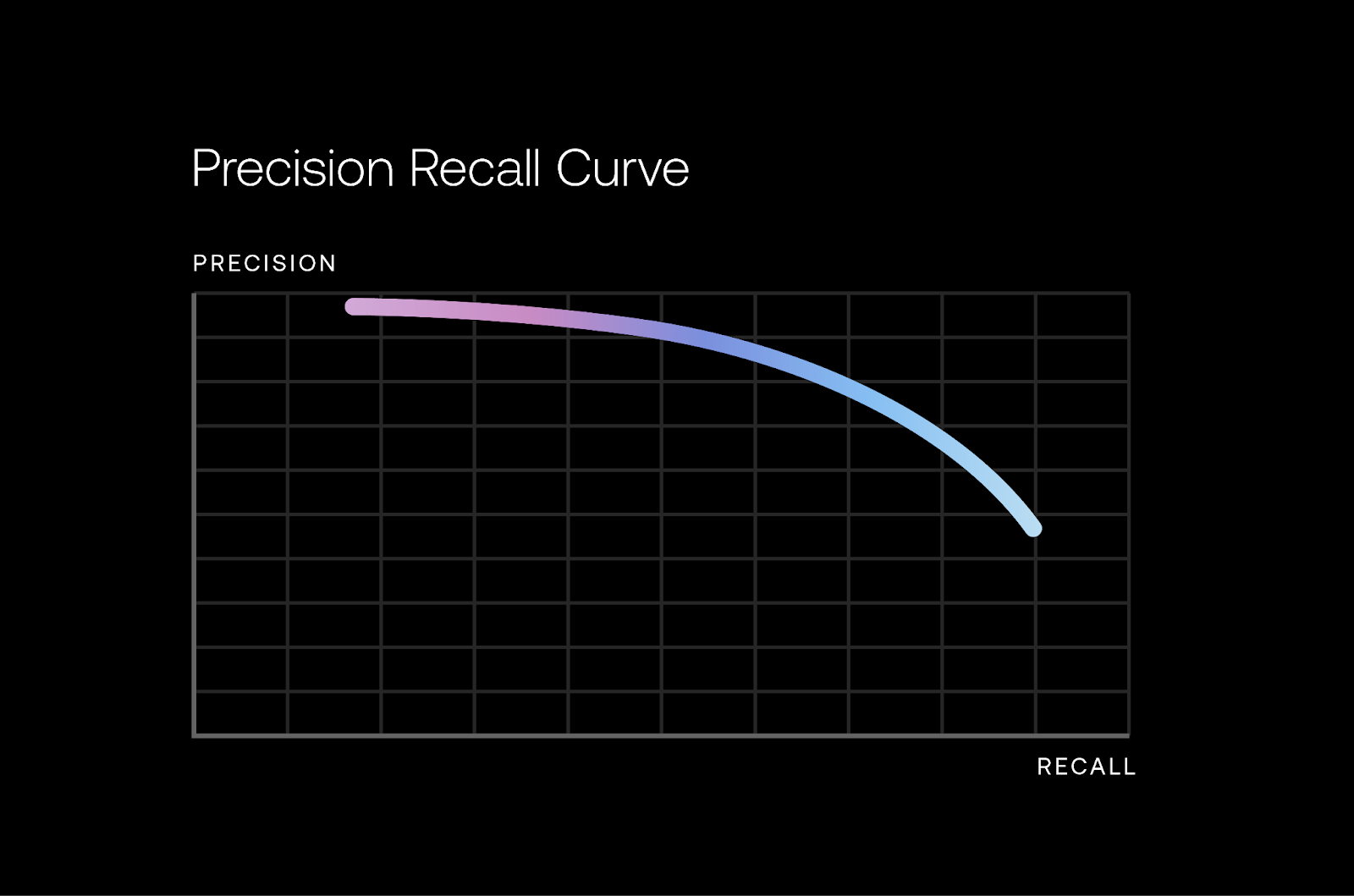
Precision and recall
Precision defines what proportion of positive identifications were correct and is calculated as follows:
Precision = True Positives / True Positives + False Positives
- A model that produces no false positives has a recall of 1.0
Recall defines what proportion of actual positives were identified correctly by the model, and is calculated as follows:
Recall = True Positives / True Positives + False Negatives
- A model that produces no false negatives has a recall of 1.0
F-1 or F-n Score
F-1 is the harmonic mean of Precision and Recall, so it’s a metric that factors both scores as inputs. Perfect precision and recall yields a score of 1.0, while F-1 is 0 if either precision or recall is 0. Adopting a different value of n means you can bias the harmonic mean to favor either precision or recall depending on your needs. For example, do you care more about reducing false positives or false negatives? Safety-critical scenarios will often dictate that you can tolerate false negatives or false positives but not vice versa.
IoU (Intersection-over-Union)
This metric is the percent overlap between ground truth (data annotations) and the model’s prediction. This typically applies for 2D and 3D object detection problems, and is particularly relevant for autonomous vehicles. You can think of two intersecting rectangles, where the intersection represents your success target: the bigger the overlap, the better the model. IoU is the quotient (the result from division) when you divide the overlap over the total area of the prediction and ground truth bounding rectangles. This concept can be projected to three dimensions in which the target is the overlap of two rectilinear prisms, and the IoU is the quotient of this overlapping prism over the sum of the two intersection prisms (again, ground truth and prediction).
Time required
Some simpler model architectures and smaller datasets are quicker to train on, while more complex model architectures, higher input resolutions, and larger datasets are typically slower to train on—they take more time to achieve a performant model. While training on larger and larger datasets is helpful to improve model accuracy (datasets on the order of magnitude of 1,000 or even 10,000 samples are a great place to start), at a certain point, if additional data samples contain no new information, they aren’t apt to improve model performance, particularly on rare or “edge” cases.
Model size
A secondary constraint can be the total sum of weights in the model. The more weights, the more (GPU) memory the model consumes as it trains. There’s greater complexity when you train a model that spans multiple memory banks, whether that’s across one system to the next, or across GPUs in the same system.
Dataset size
A minimum of 1000 images or 1000 rows of tabular data is typically required to build a meaningful model. It may be possible to train on fewer examples, but with small datasets you are likely to encounter problems with your model like overfitting. Ideally your use case has the largest order-of-magnitude dataset size available to you, and if it does not, you may consider approaches like synthetic augmentation or simulation.
Compute requirements
Typically, training models is both compute-intensive and time-consuming. Some models are suited to distributed training (particularly if the graph can be frozen and copied across multiple machines). Logistic regressions are comparatively easy and quick to run, as well as SVMs, whereas larger models can take hours or even days to train. Even rudimentary algorithms like K-means clustering can be computationally intensive, and can see vast speedups from training and inference on GPUs or even dedicated AI hardware like TPUs.
Spectrum: easy to hard
- If there’s a simpler tool for the job, it makes sense to start there. Simpler models include logistic regression and support vector machines (SVMs).
- That said, the boundaries between one class and another won’t always be smooth or “differentiable” or “continuous.” So sometimes more sophisticated tools are necessary.
- Random Forest Classifiers and Gradient Boosted Machines can typically handle easier vision classification challenges like the Iris dataset.
- Larger datasets and larger models typically require longer training times. So when more sophisticated models are required to achieve high accuracy, often it will take more time, more fine tuning, and a larger compute/storage budget to train the next model.
Training ML models shouldn’t be a daunting proposition given the cornucopia of tools available today. It’s never been easier to get started.That said, don’t let ML be a solution looking for a problem. Prove that simpler approaches aren’t more effective before you land on a CNN, DNN, or LSTM as the ideal solution. Training models can feel like an art, but really it’s best to approach it as a science. Hyperparameters and quirks in your dataset may dictate outcomes, but dig in deeper: eventually you can prove or disprove hypotheses as to what’s causing better or worse outcomes. It’s important to be systematic and methodical: it’s best to keep an engineer’s log or notebook. Tracking hyperparameters in GitHub is largely insufficient; you should ruthlessly test your models for regressions, track aggregate and specific performance metrics, and use tooling where possible to take the tediousness out of writing scripts.
