
















Engineering
Why is ChatGPT so good?
by Clemens Viernickel on January 25th, 2023
Instead of simply predicting the next word(s), Large Language Models (LLMs) can now follow human instructions and provide useful responses. These advancements are made possible by fine-tuning them with specialized instruction datasets and a technique called Reinforcement Learning with Human Feedback (RLHF).
In this blog, we review how these new capabilities emerged and explore how to fine-tune them, including using RLHF.
One year ago, if you wanted to write a wedding speech, formulate a complaint email to your landlord, summarize a scientific article or debug code, most people would probably not have considered using an LLM. Today, this has changed. The most recent versions of OpenAI’s GPT-3 and ChatGPT, and other powerful language models like DeepMind’s Sparrow or Anthropic’s Claude, can perform these tasks and much more. The models are both capable and fun to talk to, surpassing many expectations of researchers and practitioners that previously used the original GPT-3 only. Developers and companies are starting to use these LLMs for just about any language task ranging from scientific discovery over legal matters to even medical advice. But how did we get here? What changed?
In simple terms, language models predict the next token (that is, a word or part of a word) based on a specific input called “prompt.”
These models started to move into the spotlight with the release of Google’s seminal “Attention Is All You Need” paper (https://arxiv.org/pdf/1706.03762.pdf), introducing a Transformer architecture that was orders of magnitude more effective at language tasks compared to previous models. The text generation, summarization, and autocompletion abilities of these models, such as GPT-3 by OpenAI and RoBERTa by HuggingFace were impressive. The model also had impressive “world-knowledge” and was quite effective at “in-context learning” (given a few examples of a task, generating a solution for the previously unseen test case). However, while producing coherent text, the models required relatively advanced prompting and had significant difficulties following tasks or human instructions such as “write a story” or “debug this code.” They also were notoriously error-prone in their generations and not verbose.
For example, when trying a text generation task with the original GPT-3 like “Generate a story about the moon landing combined with Star Wars characters,” the model’s answer is coherent but also short and probably quite different from how a human would answer the same prompt.
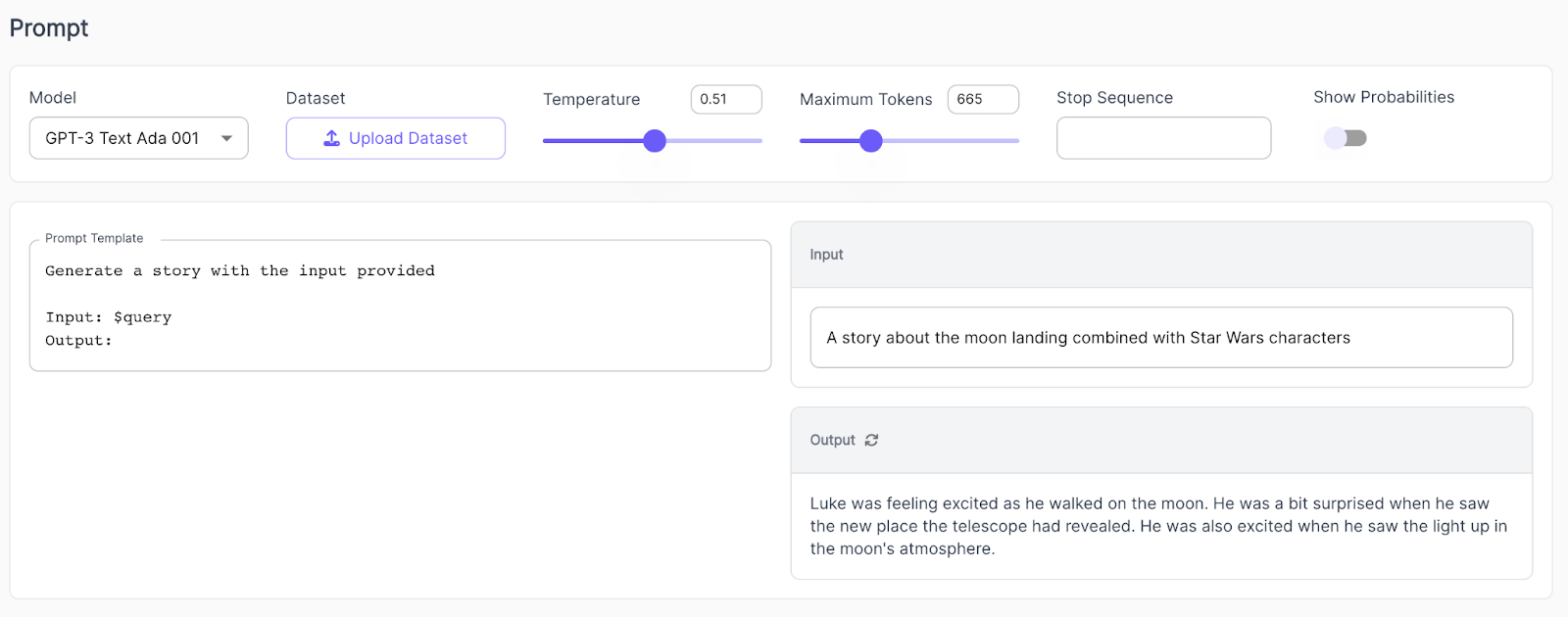
Text generation task for the initial GPT-3 Text 001 using Scale Spellbook
Side-note: We’re using Scale Spellbook to quickly create and deploy LLM apps such as the one above, including the ability to experiment with different prompts and add Human Feedback annotations. Get early access to Spellbook here: https://scale.com/spellbook.
The result is dramatically different when giving the same task to Open AI's ChatGPT.

It outputs a coherent, verbose story, including multiple Star Wars characters, even combining more advanced pieces of a Star Wars-style story plot with the moon landing and weaving in characteristic quotes of certain characters.
Something similar can be observed for a simple coding task. When prompting the initial GPT-3, it is clear that the model can write code but does not really understand the context of the instruction. The result is a code that would not work for the purpose.
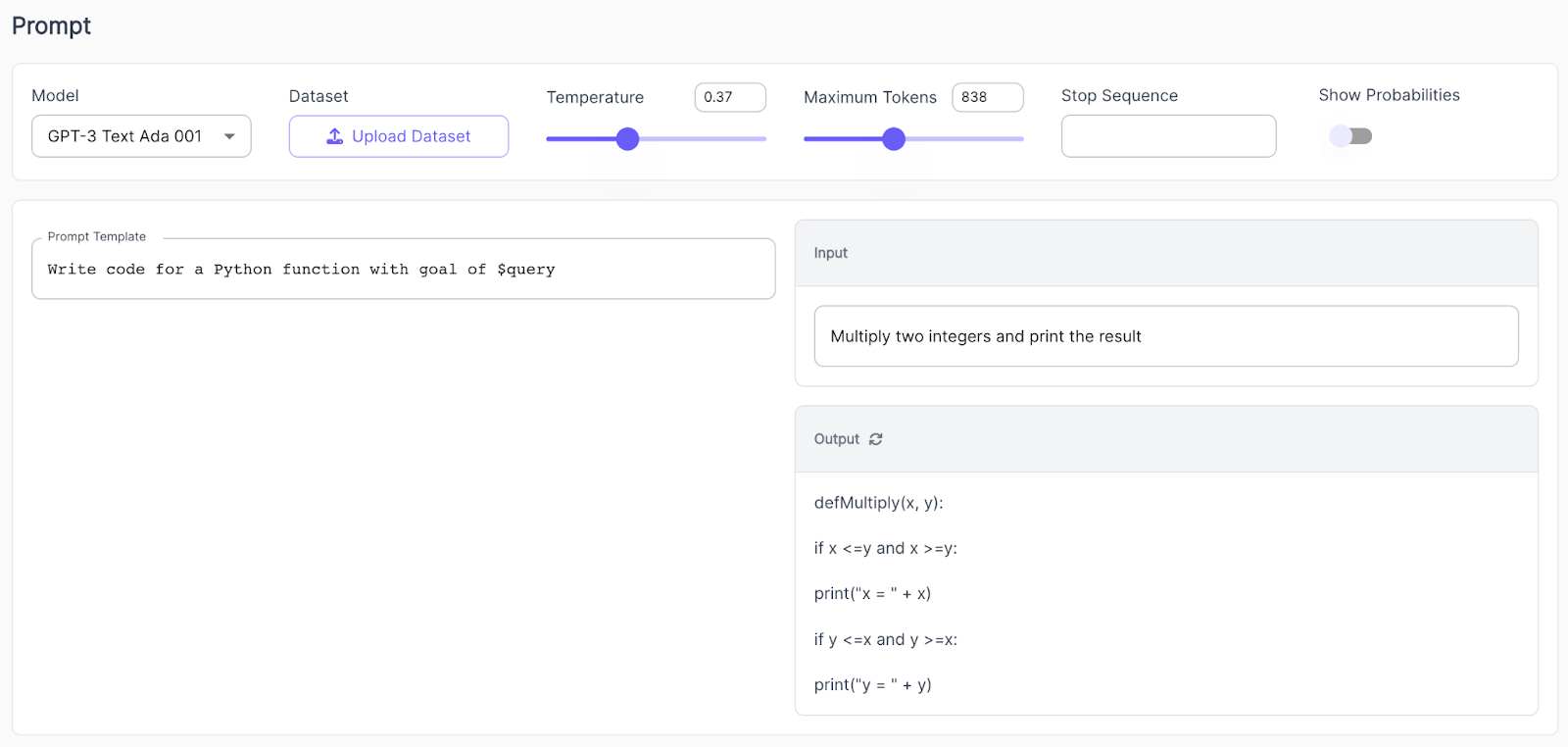
Contrast this to ChatGPT:

The answer is succinct and perfectly solves the problem. The model even includes a reference as to how to use the function, demonstrating just how well the model understood the instruction.
For a more detailed exploration of comparing multiple versions of GPT-3, see here.
But how did LLMs suddenly get so good at answering questions?
The evolution of GPT-3 and related models
The initial GPT-3 model
GPT-3, released in 2020, is a whopping 175B parameter model pre-trained on a corpus of more than 300B tokens. From this pre-training, the model has extensive knowledge of facts and common sense, as well as the ability to generate coherent language. Still, the model did not impress everyone. On the surface, it seems that GPT-3 is not particularly adept at many of the tasks, reasoning, and instruction-following that the later versions, including ChatGPT, excel at. However, several researchers and practitioners argue that many of the abilities exhibited by ChatGPT are already present in the original GPT-3, but not surfaced due to the lack of fine-tuning (e.g. see Yao Fu).
Training on code
OpenAI continued to train GPT-3 on a combination of text and a large corpus of code, resulting in the Code-Davinci-002 or Codex model (https://arxiv.org/abs/2107.03374). Including code in the training data surfaced abilities such as code understanding, code generation, and more complex reasoning on regular text tasks. As a result, GitHub’s Copilot model has gained meaningful adoption by the developer community. There are also open-source implementations of code-generating models, such as SalesForce’s CodeGen.
Fine-tuning on instruction datasets
The next impressive milestone came with fine-tuning the LLMs using instruction datasets (IntructGPT paper, FLAN paper). Instruction data is understood as pairs of specific input templates, such as “translate sentence Y” and “explain how to make X,” paired with correct output statements generated by human annotators. These datasets typically take a lot of time to build, as they require creative writing and language skills by human annotators and sometimes even specialized knowledge about the subject matter at hand.

Source: https://arxiv.org/abs/2109.01652
Note: If you are looking to build an instruction dataset, we at Scale have years of experience quickly building large-volume instruction datasets for some of the world’s most ambitious AI teams. Contact language-models@scale.com to learn more, or check out our website here.
These fine-tuned models demonstrated a much stronger ability to follow human instructions when prompted and generalize very well to previously unseen tasks with so-called zero-shot text generation. They can effectively solve tasks such as writing a coherent short story, email, or C++ function even if they were not trained on the specific prompt.
Introducing Reinforcement learning with Human Feedback (RLHF)
However, the instruction-tuned models still regularly provide short, biased (even toxic) or wrong answers. They might take a political position or answer the request for a speech with a single-sentence response. They also have no conception of what they do not know or which kind of requests would be inadequate, making them inherently unsafe for most practical applications.
To combat these issues, OpenAI applied a particular type of instruction fine-tuning called Reinforcement Learning with Human Feedback (RLHF). The basic idea is to train an additional reward model that rates how good a model's response is from the perspective of a human to guide the model's learning process. Then use this reward model to fine-tune the original language model using reinforcement learning.
Note: If you are interested in doing RLHF or a comparable technique, we’ve got you covered with all the required infrastructure and human annotators. Simply reach out to language-models@scale.com
Applying this technique yielded strong results with regards to the practical shortcomings of the previous instruction-tuned models. The RLHF-trained models can provide answers that align with human values, generate more verbose responses, and reject questions that are either inappropriate or outside the knowledge space of the model. The ability to engage in actual dialogue in maintaining context is another ability surfaced in ChatGPT, which makes it particularly fun and helpful. Besides ChatGPT, DeepMind’s Sparrow model and Anthropic’s Claude model are other examples of RLHF in action (see here for a comparison of ChatGPT and Claude).
At Scale, we have seen this in practice with many of our customers and our own models. The models fine-tuned with human feedback consistently outperform those without across-the-board.
Source: Import AI Newsletter
The Human Preference score on the y-axis measures the response of the individual models on the x-axis as rated by humans. Each model has a human preference score for a variant fine-tuned with human feedback data and one without. Source: Scale AI
How to implement RLHF
If you’re somewhat new to reinforcement learning, we highly recommend Andrey Kaparthy’s introduction here: http://karpathy.github.io/2016/05/31/rl/!
There are three steps to do RLHF: collect demonstration data to fine-tune a language model, collect comparison data and train a reward model, and finally perform reinforcement learning using the previous two steps! Let’s dive in!

Figure from OpenAI’s paper “Training language models to follow instructions with human feedback” (https://arxiv.org/pdf/2203.02155.pdf).
PPO: Proximal Policy Optimization is a reinforcement learning algorithm introduced by OpenAI (learn more).
Preface: Unsupervised pre-training
The prerequisite for doing RLHF is to have a large language model (which includes having access to the weights), that is pre-trained on a huge corpus of text, such as BLOOM.
Step 1: Collect human demonstration data to fine-tune the language model
The first step is to demonstrate to the language model what an appropriate response to a given prompt should look like. For this purpose, we take a set of prompts and present them to human annotators, which would write a complete response.
While most annotators can provide the above response, some questions might require highly specialized knowledge.
These prompt and response pairs are then used to fine-tune the language model using supervised learning, which later is used as the (supervised) policy in reinforcement learning.
Note: At Scale, we can generate this type of demonstration data across a wide range of languages and use cases. We can quickly recruit highly specialized annotators and massively scale up the volume of annotations while maintaining high-quality standards.
Step 2: Generate outputs and collect comparison data to train a reward model
In the next step, we will take a set of prompts and generate multiple responses from the fine-tuned model for each prompt. Then, we use human annotators to rank these model responses for the given prompt (or just compare two) from best to worst w.r.t. to their correctness and the likelihood that they stem from a human.
These rankings are then used to train a separate reward model. This reward model will then output a quality score for any given model response to a given prompt.
Note: If you are looking for expert raters who can annotate the model outputs to train your reward model, we have thousands of highly trained annotators across any number of domains to get you started!
Step 3: Perform reinforcement learning by combining the fine-tuned model outputs and the reward model
In the third step, we take a new set of prompts and feed them to the fine-tuned model from step 1 to generate responses. Then, the reward model scores the responses based on the human preferences it was trained on in step 2. This simulates the rating of model responses we did manually in step 2. We then use the proximal policy optimization algorithm (PPO) to update the supervised model from step 1. Improving the reward model and the reinforcement learning in step 3 are done continuously, alternating between updating the reward model (with fixed policy) and updating the policy (fixed reward model).
Note: If you’re interested in trying RLHF but currently do not have the resources to try it out, feel free to contact language-models@scale.com to trial our all-in-one RLHF service.
If you want to learn more about our own work in RLHF, check out our collaboration with Carper AI, HuggingFace, Multi and Humanloop here: https://carper.ai/instruct-gpt-announcement/
Alternatives to RLHF When Using LLMs as a Service
The astute observer might have realized a problem with the above. For LLMs like GPT-3 that are used “as-a-service,” we do not have access to the weights themselves, so we cannot do fine-tuning and consequently cannot do RLHF.
However, there are some practical alternatives to consider:
-
Train your own language model or use an open-source LLM with weights available. While training proprietary models is gaining more traction, this comes at considerable cost and effort. Using an open-source LLM is one of the most common options among our customers. This is especially true for companies that want to avoid sending data to OpenAI in the process of training and fine-tuning their LLM.
-
Instead of updating the weights of GPT-3, train a reward model and use it to do rejection sampling on calls to GPT-3. In practice, this means that when using GPT-3, you could ensure it does not give inappropriate or wrong answers when calling the model. While this approach does not yield a better-performing LLM, it can still remedy some of the practical shortcomings of GPT-3 and make it safer to use in production.
-
Use the comparison data collected in step 2 to directly fine-tune GPT-3 via OpenAI’s fine-tuning API. This approach misses the iterative part, but it can still help to improve the responses of GPT-3 in practice, especially if you have a very specialized use case for the LLM, such as giving legal or medical advice.
At Scale, we can help with all three of these approaches by providing both the relevant annotations and infrastructure to train and fine-tune state-of-the-art language models.
Recap
To summarize, LLMs have made incredible progress over the past few years and even months. Novel techniques to fine-tune these models have resulted in groundbreaking models such as ChatGPT, which can generate genuinely helpful answers to a wide range of tasks. Most notably, due to the inclusion of human feedback in the fine-tuning process, the newer LLMs seem to be very well aligned with instructions as well as with human values and understand their own scope very well.
At Scale, we are proud to help some of the most ambitious AI companies train and fine-tune LLMs with human feedback.
If you want to get started with RLHF or are looking for human feedback data, both for demonstration or comparison, make sure to shoot us an email at language-models@scale.com.