Products








Solutions

Retail & eCommerce

Defense

Logistics

Autonomous Vehicles

Robotics

AR/VR

Content & Language

Smart Port Lab

Federal LLMs
Resources
Company
Customers
See all customersDiffusion Models: A Practical Guide
Diffusion models have the power to generate any image that you can imagine. This is the guide you need to ensure you can use them to your advantage whether you are a creative artist, software developer, or business executive.
By Vivek Muppalla and Sean Hendryx on October 19th, 2022
Contents
With the Release of Dall-E 2, Google’s Imagen, Stable Diffusion, and Midjourney, diffusion models have taken the world by storm, inspiring creativity and pushing the boundaries of machine learning.
These models can generate a near-infinite variety of images from text prompts, including the photo-realistic, the fantastical, the futuristic, and of course the adorable.

These capabilities redefine what it means for humanity to interact with silicon, giving us superpowers to generate almost any image that we can imagine. Even with their advanced capabilities, diffusion models do have limitations which we will cover later in the guide. But as these models are continuously improved or the next generative paradigm takes over, they will enable humanity to create images, videos, and other immersive experiences with simply a thought.
In this guide, we explore diffusion models, how they work, their practical applications, and what the future may have in store.
Generative models are a class of machine learning models that can generate new data based on training data. Other generative models include Generative adversarial networks (GANs), Variational Autoencoders (VAEs), and Flow-based models. Each can produce high-quality images, but they all have limitations that make them inferior to diffusion models.
At a high level, Diffusion models work by destroying training data by adding noise and then learn to recover the data by reversing this noising process. In Other words, Diffusion models can generate coherent images from noise.
Diffusion models train by adding noise to images, which the model then learns how to remove. The model then applies this denoising process to random seeds to generate realistic images.

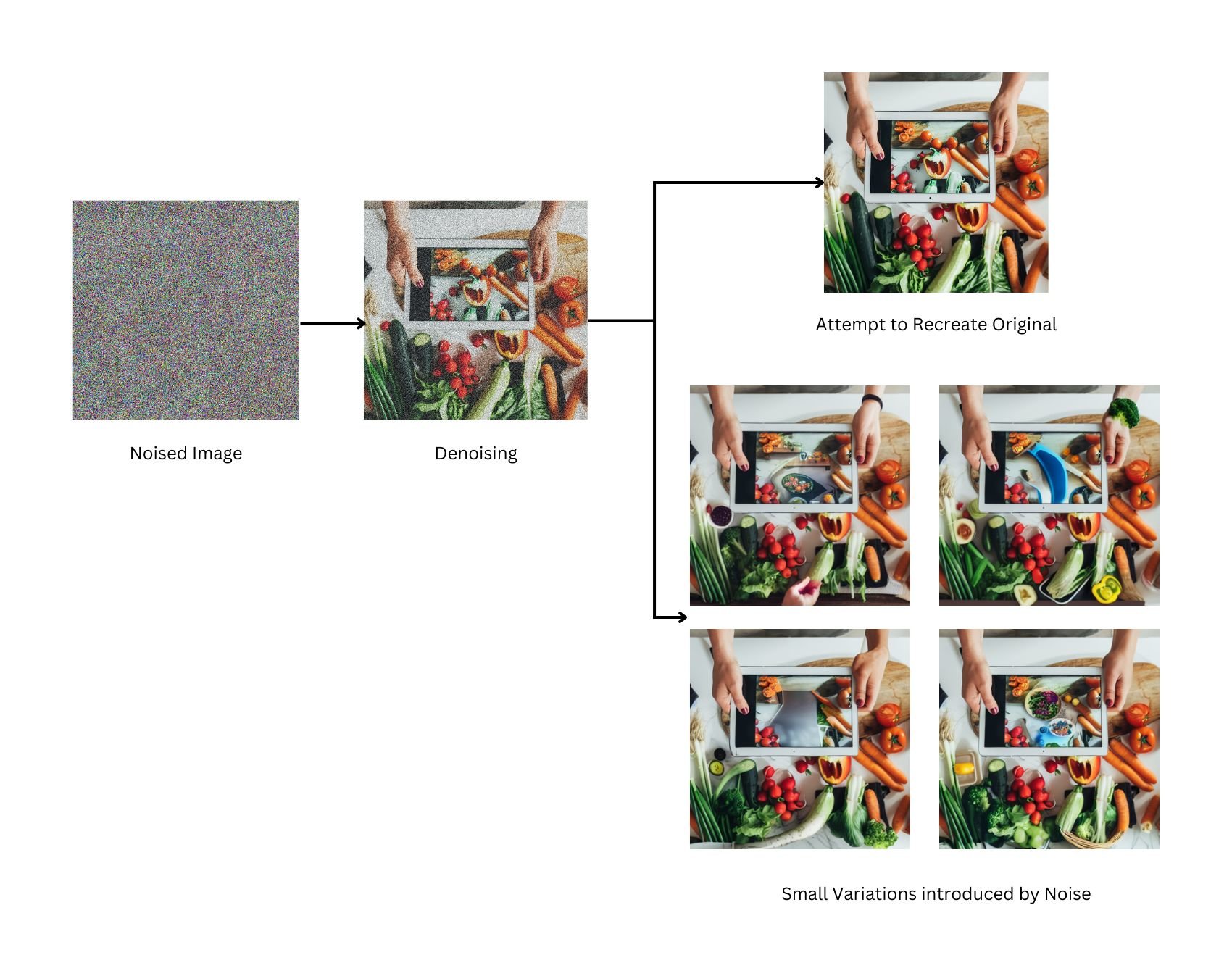
Combined with text-to-image guidance, these models can be used to create a near-infinite variety of images from text alone by conditioning the image generation process. Inputs from embeddings like CLIP can guide the seeds to provide powerful text-to-image capabilities.
Diffusion models can complete various tasks, including image generation, image denoising, inpainting, outpainting, and bit diffusion.
Popular diffusion models include Open AI’s Dall-E 2, Google’s Imagen, and Stability AI's Stable Diffusion.
- Dall-E 2: Dall-E 2 revealed in April 2022, generated even more realistic images at higher resolutions than the original Dall-E. As of September 28, 2022 Dall-E 2 is open to the public on the OpenAI website, with a limited number of free images and additional images available for purchase.
- Imagen is Google’s May 2022, version of a text-to-image diffusion model, which is not available to the public.
- Stable Diffusion: In August 2022, Stability AI released Stable Diffusion, an open-source Diffusion model similar to Dall-E 2 and Imagen. Stability AI’s released open source code and model weights, opening up the models to the entire AI community. Stable Diffusion was trained on an open dataset, using the 2 billion English label subset of the CLIP-filtered image-text pairs open dataset LAION 5b, a general crawl of the internet created by the German charity LAION.
- Midjourney is another diffusion model released in July 2022 and available via API and a discord bot.
Simply put, Diffusion models are generative tools that enable users to create almost any image they can imagine.
Diffusion models represent that zenith of generative capabilities today. However, these models stand on the shoulders of giants, owing their success to over a decade of advancements in machine learning techniques, the widespread availability of massive amounts of image data, and improved hardware.
For some context, below is a brief outline of significant machine learning developments.
- In 2009 at CVPR, the seminal Imagenet paper and dataset were released, which contained over 14 million hand-annotated images. This dataset was massive at the time, and it remains relevant to researchers and businesses building models today.
- In 2014, GANs were introduced by Ian Goodfellow, establishing powerful generative capabilities for machine learning models.
- In 2018 LLM’s hit the scene with the original GPT release, followed shortly by its successors GPT-2, and the current GPT-3, which have text generation capabilities.
- In 2020, NeRFs allowed the world to produce 3D objects from a series of images, and known camera poses.
- Over the past few years, Diffusion models have continued this evolution, giving us even more powerful generative capabilities.
What about diffusion models makes them so strikingly different from their predecessors? The most apparent answer is their ability to generate highly realistic imagery and match the distribution of real images better than GANs. Also, diffusion models are more stable than GANs, which are subject to mode collapse, where they only represent a few modes of the true distribution of data after training. This mode collapse means that in the extreme case, only a single image would be returned for any prompt, though the issue is not quite as extreme in practice. Diffusion models avoid the problem as the diffusion process smooths out the distribution, resulting in diffusion models having more diversity in imagery than GANs.
Diffusion models also can be conditioned on a wide variety of inputs, such as text for text-to-image generation, bounding boxes for layout-to-image generation, masked images for inpainting, and lower-resolution images for super-resolution.
The applications for diffusion models are vast, and the practical uses of these models are still evolving. These models will greatly impact Retail and eCommerce, Entertainment, Social Media, AR/VR, Marketing, and more.
Web applications such Open AI’s Dall-E 2 and Stable Diffusion’s DreamStudio make diffusion models readily available. These tools provide a quick and easy way for beginners to start with diffusion models, allowing you to generate images with prompts and perform inpainting and outpainting. DreamStudio offers more control over the output parameters, while Dall-E 2’s interface is simpler with fewer frills. Each platform provides free credits to new users, but will charge a usage fee once those credits are depleted.
- DreamStudio: DreamStudio from Stability AI is a quick way for users to experience Stable Diffusion without worrying about the infrastructure details. There is tooling for image generation, inpainting, and outpainting. Uniquely, the interface enables users to specify a random seed, providing the ability to traverse the latent space while holding a prompt fixed (more to come on this later). New users get 200 free credits.
- Dall-E 2: OpenAI recently announced that Dall-E 2 is now generally available to all users, coming out of its previously closed beta. Dall-E 2 provides a simple user interface without many frills, to generate images, inpainting, and outpainting.
- Local Installation:
- Stability AI broke headlines when it announced that it was open-sourcing both the model weights and source code for its Diffusion model Stable Diffusion.
- You can download and install Stable Diffusion on your local computer and integrate its capabilities into applications and workflows.
- Other models, such as Dall-E 2, are currently only available via API or web app as their models are not open-source like Stable Diffusion.
You can also search through a wide array of curated images on aggregation sites like Lexica.art, which provides an even easier way to get started and get inspired by what the broader community has been creating and learn how to build better prompts
Prompts are how you can control the outputs for Diffusion models. Diffusion models are verbose and take two primary inputs and translate these into a fixed point in its model’s latent space, a seed integer, and a text prompt. The seed integer is generally automatically generated, and the user provides the text prompt. Continuous experimentation via Prompt engineering is critical to getting the perfect outcomes. We explored Dall-E 2 and Stable Diffusion and have consolidated our best tips and tricks to getting the most out of your prompts, including prompt length, artistic style, and key terms to help you sculpt the images you want to generate.
How to prompt
In general, there are three main components to a prompt:
Frame + Subject + Style + an optional Seed.
1. Frame - The frame of an image is the type of image to be generated. This is combined with the Style later in the prompt to provide an overall look and feel of the image. Examples of Frames include photograph, digital illustration, oil painting, pencil drawing, one-line drawing, and matte painting.
- The following examples are modified versions of the base prompt "Painting of a person in a Grocery Store," in the frame of an oil painting, a digital illustration, a realistic photo, and a 3D cartoon.
- Diffusion models typically default to a “picture” frame if not specified, though this is dependent on the subject matter. By specifying a frame of an image, you control the output directly.
- By modifying the frame to “Polaroid” you can mimic the output of a polaroid camera, complete with large white borders.
- Pencil Drawings can be produced as well.
- And as already covered, different painting techniques can be applied.
- Frames provide a rough guide for the output type the diffusion model should generate. But in order to create remarkable images, a good subject and refined style should also be added to your prompts. We will cover subjects next and then detail tips and tricks for combining frames, subjects, and styles to fine-tune your images.





2. Subject - The main subject for generated images can be anything you can dream up.
- Diffusion models are built largely from publicly available internet data and are able to produce highly accurate images of objects that exist in the real world.
- However, Diffusion models often struggle with compositionality, so ideally, limiting your prompts to one to two subjects is best.
- Sticking to one or two subjects produces generally good results, for example "Chef Chopping Carrots on a cutting board."
- Even though there is some confusion here with a knife chopping another knife, there are chopped carrots in the scene, which is generally close to the original prompt.
- However, expanding to more than two subjects can produce unreliable and sometimes humorous results:
- Diffusion models tend to fuse two subjects into a single subject if the subjects are less common. For example, the prompt “a giraffe and an elephant” yields a giraffe-elephant hybrid rather than a single giraffe and a single elephant. Interestingly, there are often two animals in the scene, but each is typically a hybrid.
- Some attempts to prevent this, including adding in a preposition like “beside,” have mixed results but are closer to the original intent of the prompt.
- This issue appears subject-dependent, as a more popular pair of animals, such as “a dog and a cat,” generates distinct animals without a problem.








3. Style - The style of an image has several facets, key ones being the lighting, the theme, the art influence, or the period.
- Details such as “Beautifully lit”, “Modern Cinema”, or “Surrealist”, will all influence the final output of the image.
- Referring back to the prompt of "chefs chopping carrots," we can influence this simple image by applying new styles. Here we see a “modern film look” applied to the frames of “Oil Painting” and “Picture.”
- The tone of the images can be shaped by a style, here we see “spooky lighting.”
- You can fine-tune the look of the resulting images by slightly modifying the style. We start with a blank slate of “a house in a suburban neighborhood.”
- By adding “beautifully lit surrealist art” we get much more dynamic and intense images.
- Tweaking this we can get a spooky theme to the images by replacing “beautifully lit” with the phrase “spooky scary.”
- Apply this to a different frame to get the desired output, here we see the same prompt with the frame of an oil painting.
- We can then alter the tone to “happy light” and see the dramatic difference in the output.
- You can change the art style to further refine the images, in this case switching from “surrealist art” to “art nouveau.”
- As another demonstration of how the frame influences the output, here we switch to “watercolor” with the same style.
- Different seasons can be applied to images to influence the setting and tone of the image.
- There is a near-infinite variety of combinations of frames and styles and we only scratch the surface here.
- Artists can be used to fine-tune your prompts as well. The following are versions of the same prompt, "person shopping at a grocery store," styled to look like works of art from famous historic painters.
- By applying different styles and frames along with an artist, you can create novel artwork.
- Start with a base prompt of “painting of a human cyborg in a city {artist} 8K highly detailed.”
- While the subject is a bit unorthodox for this group, each painting fits the expected style profile of each artist.
- We can alter the style by modifying the tone, in this case, to “muted tones”:
- You can further alter the output by modifying both the frame and the tone to get unique results, in this case, a frame of a “3D model painting” with neon tones.
- Adding the qualifier, “the most beautiful image you’ve ever seen” yields eye-catching results.
- And depictions such as “3D model paintings” yield unique, novel works of art.
- By modifying the frame and style of the image, you can yield some amazing and novel results. Try different combinations of style modifiers, including “dramatic lighting”, or “washed colors” in addition to the examples that we provided to fine-tune your concepts further.
- We hardly scratched the surface in this guide, and look forward to amazing new creations from the community.





















4. Seed
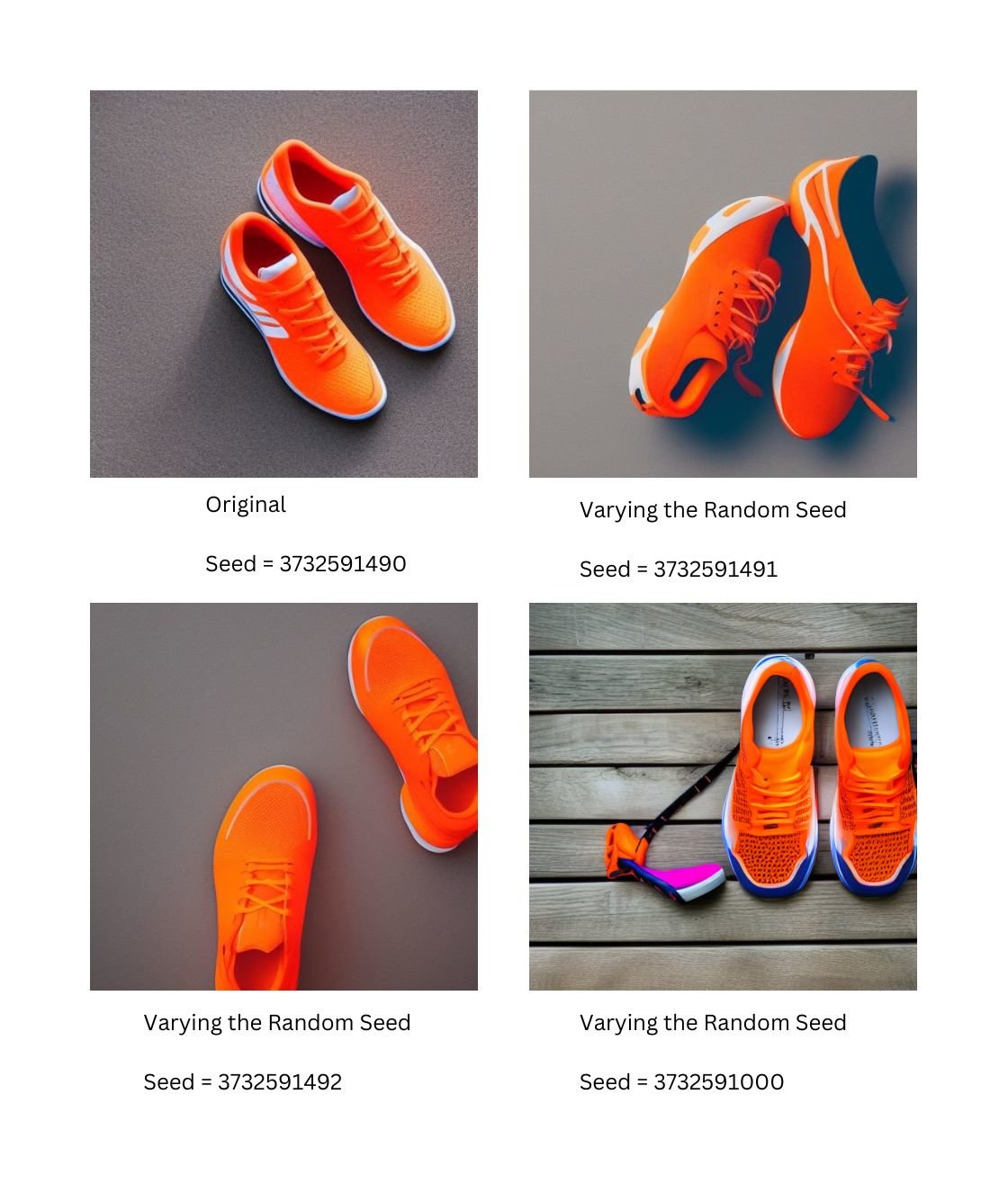
- A combination of the same seed, same prompt, and same version of Stable Diffusion will always result in the same image.
- If you are getting different images for the same prompt, it is likely caused by using a random seed instead of a fixed seed. For example, "Bright orange tennis shoes, realistic lighting e-commerce website" can be varied by modifying the value of the random seed.
- Changing any of these values will result in a different image. You can hold the prompt or seed in place and traverse the latent space by changing the other variable. This method provides a deterministic way to find similar images and vary the images slightly.
- Varying the prompt to "bright blue suede dress shoes, realistic lighting e-commerce website" and holding the seed in place at 3732591490 produces results with similar compositions but matching the desired prompt. And again, holding that prompt in place and traversing the latent space by changing the seed produces different variations:

To summarize a good way to structure your prompts is to include the elements of “[frame] [main subject] [style type] [modifiers]” or “A [frame type] of a [main subject], [style example]” And an optional seed. The order of these exact phrases may alter your outcome, so if you are looking for a particular result it is best to experiment with all of these values until you are satisfied with the result.
4. Prompt Length
Generally, prompts should be just as verbose as you need them to be to get the desired result. It is best to start with a simple prompt to experiment with the results returned and then refine your prompts, extending the length as needed.
However, many fine-tuned prompts already exist that should be reused or modified.
Modifiers such as "ultra-realistic," "octane render," and "unreal engine" tend to help refine the quality of images, as you can see in some of the examples below.
- “A female daytrader with glasses in a clean home office at her computer working looking out the window, ultra realistic, concept art, intricate details, serious, highly detailed, photorealistic, octane render, 8 k, unreal engine”

- “portrait photo of a man staring serious eyes with green, purple and pink facepaint, 50mm portrait photography, hard rim lighting photography–beta –ar 2:3 –beta –upbeta”

- “Extremely detailed wide angle photograph, atmospheric, night, reflections, award winning contemporary modern interior design apartment living room, cozy and calm, fabrics and textiles, geometric wood carvings, colorful accents, reflective brass and copper decorations, reading nook, many light sources, lamps, oiled hardwood floors, color sorted book shelves, couch, tv, desk, plants”

- “Hyperrealistic and heavy detailed fashion week runway show in the year 2050, leica sl2 50mm, vivid color, high quality, high textured, real life”

- “Full-body cyberpunk style sculpture of a young handsome colombian prince half android with a chest opening exposing circuitry and electric sparks, glowing pink eyes, crown of blue flowers, flowing salmon-colored silk, fabric, raptors. baroque elements. full-length view. baroque element. intricate artwork by caravaggio. many many birds birds on background. trending on artstation, octane render, cinematic lighting from the right, hyper realism, octane render, 8k, depth of field, 3d”

- “Architectural illustration of an awesome sunny day environment concept art on a cliff, architecture by kengo kuma with village, residential area, mixed development, high - rise made up staircases, balconies, full of clear glass facades, cgsociety, fantastic realism, artstation hq, cinematic, volumetric lighting, vray”

5. Additional Tips
A few additional items are worth mentioning.
Placing the primary subject of the image closer to the beginning of the prompt tends to ensure that subject is included in the image. For instance, compare the two prompts
- "A city street with a black velvet couch" at times will miss the intent of the prompt entirely and the resulting image will not include a couch.

- By rearranging the prompt to have the keyword "couch" closer to the beginning of the prompt, the resulting images will almost always contain a couch.

There are combinations of subject and location that tend to yield poor results. For instance, "A black Velvet Couch on the surface of the moon" yields uneven results, with different backgrounds and missing couches entirely. However, a similar prompt, "A black velvet couch in a desert" tends to reflect the intent of the prompt, capturing the velvet material, the black color, and the characteristics of the scene more accurately. Presumably, there are more desert images contained in the training data, making the model better at creating coherent scenes for deserts than the moon.


Prompt engineering is an ever-evolving topic, with new tips and tricks being uncovered daily. As more businesses discover the power of diffusion models to help solve their problems, it is likely that a new type of career, "Prompt Engineer" will emerge.
As powerful as they are, Diffusion models do have limitations, some of which we will explore here. Disclaimer: given the rapid pace of development, these limitations are noted as of October 2022.
- Face Distortion: Faces become substantially distorted when the number of subjects exceeds 3. For example, "a family of six in a conversation at a cafe looking at each other and holding coffee cups, a park in the background across the street leica sl2 50mm, vivid color, high quality, high textured, real life", the faces become substantially distorted.

- However, increasing the number of subjects in the prompt causes the faces to become substantially distorted. For example this updated prompt, “a family of six in a conversation at a cafe looking at each other and holding coffee cups, a park in the background across the street leica sl2 50mm, vivid color, high quality, high textured, real life,” results in the following:

- Text generation: In an ironic twist, diffusion models are notoriously bad at generating text within images, even though the images are generated from text prompts, which diffusion models handle well. For the prompt "a man at a conference wearing a black t shirt with the word SCALE written in neon text" the generated image will include words on the shirt in the best case, but will not recreate "Scale", in this case instead including the letters "Sc-sa Salee". In other cases, the words will be on signs, the wall, or not included at all. This will likely to be fixed in future versions of these models, but it is interesting to note.

- Limited Prompt Understanding: For some images it does require a lot of massaging of the prompt to get the desired output, reducing the potential efficiency of these models for a productivity tool, though they are still a net productivity add.
Diffusion models' flexibility gives them more capabilities than just pure image generation.
- Inpainting is an image editing capability that enables users to modify regions of an image and replace those regions with generated content from the diffusion model. The model references surrounding pixels to ensure that the generations fit the context of the original image. Many tools enable changes within an image (real-world images or generated images) by "erasing" or applying a mask to a specific image region and then asking the model to fill in the image with new content. With inpainting, you start with a real-world or generated image. In this case, the image is of a model leaning against a wall in a modern city.

- You then apply a "mask" to the areas of the image you would like to replace, similar to erasing areas of the image. First, we will replace the jacket that the model is wearing.

- Then, we will generate new clothing for the model to wear, in this case a beautiful fancy gown shiny with pink highlights.

- Or a bright purple and pink wool jacket with orange highlights and highly detailed.

- The images above maintain the original pose, but these models can also suggest new poses, in this case, moving the arm down to the side, as seen in this example, "A glowing neon jacket purple and pink"

- Diversity of materials is demonstrated as well with "A leather jacket with gold studs"

- And also with "A shiny translucent coat neon"

- Inpainting can also replace background elements, either by simply removing them and filling in the background, or generating new backgrounds that did not exist in the original image. Start with Masking out the poles in the background:

- To generate a new background, apply a mask to and generate new scenes, in this case "a futuristic cityscape with flying cars."

As you can see, inpainting is quite powerful for editing images quickly and generating new scenes dynamically.
In the future, expect the capabilities of these tools to be even more efficient, without requiring the user to edit a mask. By simply describing the desired edits, i.e., “Replace the background with a futuristic cityscape," the image will automatically be edited, with no mouse clicks or keystrokes needed.
2. Outpainting
Outpainting enables users to extend their creativity by continuing an image beyond its original borders - adding visual elements in the same style, or taking a story in new directions simply by using natural language description.
Starting with a real-world image or a generated image, you can extend that image beyond the original borders until you have a larger, coherent scene.
- Real-world image outpainting
- Start by uploading an image and selecting a region on the outside border where you would like to extend the image.

- Similar to inpainting, you then generate prompts that generate coherent scenes that extend the original image.

- Generated Image Inpainting works in much the same way. Start by generating a scene that will serve as the seed. Outside scenes lend themselves to more expansive outpainting, so we will start with “central park looking at the skyline with people on the grass in impressionist style."

- Now add in a man playing frisbee with his dog.

- Note that the prompt does not specify that the skyline should remain consistent with the original image. The model automatically maintains and extends the background style, so you can focus on adding the elements you want to see.
- Finally, we will add in a family having a picnic and we have our finished image.

Outpainting requires an extra layer of prompt refinement in order to generate coherent scenes, but enables you to quickly create large images that would take significantly longer to create with traditional methods.

Outpainting enables impressive amounts of creativity and the ability to build large-scale scenes that remain coherent in theme and style. Similar to inpainting, there is room to improve this capability by making it even simpler to generate the desired scenes by providing a single prompt and getting the exact image you are looking for.
3. Diffusion for Video Generation
As we have seen, generating static images is exciting and offers many practical applications. Several recently announced models take the capabilities of diffusion models and extend them to create videos. These capabilities have not yet made it to the hands of a broader audience but will be coming very soon.
- Meta’s Make-A-Video is a new AI system that lets people turn text prompts into brief, high-quality video clips.
- Google’s Imagen Video generates approximately 5 second videos in a similar fashion.
4. Diffusion Model Image Curation Sites
Curation sites like Lexica.art provide highly curated collections of generated images and the prompts that were used to create them. Millions of images are indexed, so there is a good chance that the image that you originally thought you would have to generate already exists and is just a quick search away. Searches are low latency, you don’t need to wait for one to two minutes for a diffusion model to generate images, and you get the images nearly instantly. This is great for experimenting or searching for types of images or exploring prompts. Lexica is also a great way to learn how to prompt to get the results you are looking for (include a couple of examples here)
The obvious application for diffusion models is to be integrated into design tools to empower artists to be even more creative and efficient. In fact, the first wave of these tools has already been announced, including Microsoft Designer which integrates Dall-E 2 into its tooling. There are significant opportunities in the Retail and eCommerce space, with generative designs for products, fully generated catalogs, alternate angle generation, and much more.
Product design will be empowered with powerful new design tools, that will enhance their creativity and provide the capability to see what products look like in the context of homes, offices, and other scenes. With advancements in 3D diffusion, full 3D renders of products can be created with a prompt. Taking this to the extreme, these 3D renders can then be printed as a 3D model and come to life in the real world.
Marketing will be transformed, as ad creative can be dynamically generated, providing massive efficiency gains, and the ability to test different creatives will increase the effectiveness of ads.
The entertainment industry will begin incorporating diffusion models into special effects tooling, which will enable faster and more cost-effective productions. This will lead to more creative and wild entertainment concepts that are limited today due to the high costs of production. Similarly, Augmented and Virtual Reality experiences will be improved with the near-real-time content generation capabilities of the models. Users will be able to alter their world at will, with just the sound of their voice.
A new generation of tooling is being developed around these models, which will unlock a wide range of capabilities.
The vast capabilities of Diffusion models are inspiring, and we don't yet know the true extent of their limitations.
Foundation models are bound to expand their capabilities over time, and progress is accelerating rapidly. As these models improve, the way humanity interacts with machines will change fundamentally. As Roon stated in his blog Text is the Universal Interface, "soon, prompting may not look like "engineering" at all but a simple dialogue with the machine."
The opportunities for advancing our society, art, and business are plentiful, but technology needs to be embraced quickly to see these benefits. Businesses need to take advantage of this new functionality or risk falling dramatically behind. We look forward to a future where humans are a prompt away from creating anything we can imagine, unlocking unlimited productivity and creativity. The best time to get started on this journey is now, and we hope that this guide serves as a stong foundation for that journey.