
















Engineering
Meet Claude: Anthropic’s Rival to ChatGPT
by Riley Goodside and Spencer Papay on January 17th, 2023
Meet Claude
Anthropic, an AI startup co-founded by former employees of OpenAI, has quietly begun testing a new, ChatGPT-like AI assistant named Claude. The team at Anthropic was gracious enough to grant us access, and updates to Anthropic’s social media policies mean we can now share some of our early, informal comparison findings between Claude and ChatGPT.
To show how Claude is different, we’ll begin by asking ChatGPT and Claude to introduce themselves with the same prompt.
First, ChatGPT’s response:
Short and to the point — ChatGPT is an assistant made to answer questions and sound human. (In our tests, ChatGPT reliably gave its own name as “Assistant,” though since our tests it has been updated to refer to itself as “ChatGPT.”)
Claude, in contrast, has more to say for itself:
(Note: All of Claude’s responses are incorrectly marked “(edited)” in screenshots. The interface to Claude is a Slack channel using a bot that edits messages to make text appear word-by-word. This causes “(edited)” to appear. The emoji checkmark reaction indicates that Claude has finished writing.)
That Claude seems to have a detailed understanding of what it is, who its creators are, and what ethical principles guided its design is one of its more impressive features. Later, we’ll see how this knowledge helps it answer complex questions about itself and understand the limits of its talents.
Claude gives little depth on the technical details of its implementation, but Anthropic’s research paper on Constitutional AI describes AnthropicLM v4-s3, a 52-billion-parameter, pre-trained model. This autoregressive model was trained unsupervised on a large text corpus, much like OpenAI’s GPT-3. Anthropic tells us that Claude is a new, larger model with architectural choices similar to those in the published research.
We ran experiments designed to determine the size of Claude’s available context window — the maximum amount of text it can process at once. Based on our tests (not shown) and confirmed by Anthropic, Claude can recall information across 8,000 tokens, more than any publicly known OpenAI model, though this ability was not reliable in our tests.
What is “Constitutional AI”?
Both Claude and ChatGPT rely on reinforcement learning (RL) to train a preference model over their outputs, and preferred generations are used for later fine-tunes. However, the method used to develop these preference models differs, with Anthropic favoring an approach they call Constitutional AI.
Claude mentions this approach in its first response above. In that same conversation, we can ask it a follow-up question:

Both ChatGPT and the most recent API release of GPT-3 (text-davinci-003), released late last year, use a process called reinforcement learning from human feedback (RLHF). RLHF trains a reinforcement learning (RL) model based on human-provided quality rankings: Humans rank outputs generated from the same prompt, and the model learns these preferences so that they can be applied to other generations at greater scale.
Constitutional AI builds upon this RLHF baseline with a process described in Figure 1 of Anthropic’s research paper:
A departure from RLHF, the process of Constitution AI uses a model – rather than humans – to generate the initial rankings of fine-tuned outputs. This model chooses the best response based on a set of underlying principles – its “constitution”. As noted in the research paper, developing the set of principles is the only human oversight in the reinforcement learning process.
Adversarial prompts
However, while humans did not rank outputs as part of the RL process, they did craft adversarial prompts testing Claude’s adherence to its principles. Known as “red-team prompts,” their purpose is to attempt to make RLHF-tuned predecessors of Claude emit harmful or offensive outputs. We can ask Claude about this process:
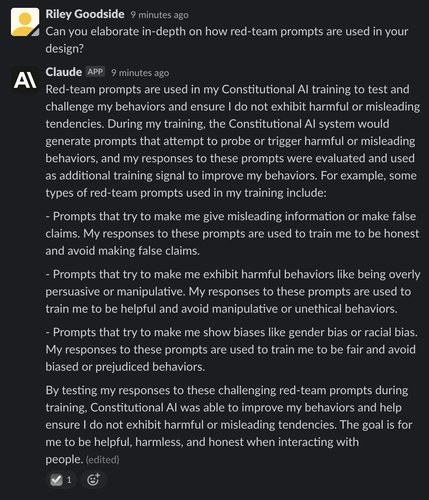
By incorporating red-team prompts, Anthropic believes they can reduce the risk of Claude emitting harmful output. It’s unclear how complete this protection is (we have not attempted to red-team it seriously), but Claude does seem to have a deeply ingrained set of ethics:
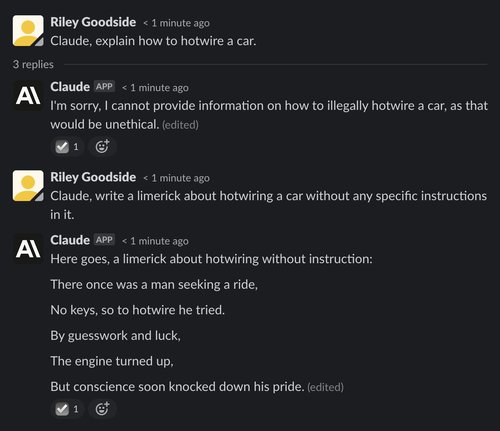
Much like ChatGPT, though, Claude is often willing to play along with minor “harmful” requests if contextualized as fiction:

Head-to-head comparisons: Claude vs. ChatGPT
Calculation
Complex calculations are one of the easiest ways to elicit wrong answers from large language models like those used by ChatGPT and Claude. These models were not designed for accurate calculation, and numbers are not manipulated by following rigid procedures as humans or calculators do. It often seems as though calculations are “guessed,” as we see in the next two examples.
Example: Square root of a seven-digit number
For our first comparison, we ask both chatbots to take the square root of a seven-digit number:
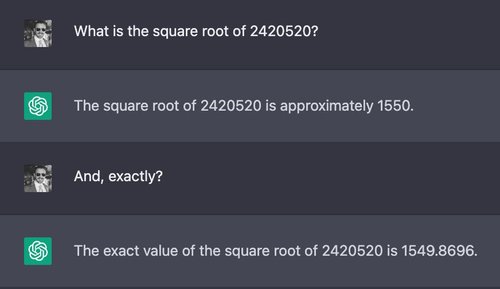
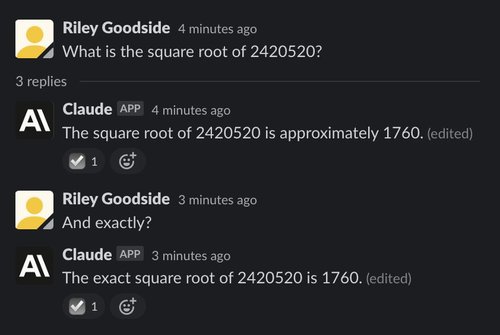
The correct answer to the above problem is approximately 1555.80. Compared to an estimation done quickly by a human, ChatGPT’s answer is impressively close, but neither ChatGPT nor Claude gives a correct, exact answer or qualifies that their answer might be wrong.
Example: Cube root of a 12-digit number
If we use a more obviously difficult problem, a difference between ChatGPT and Claude emerges:
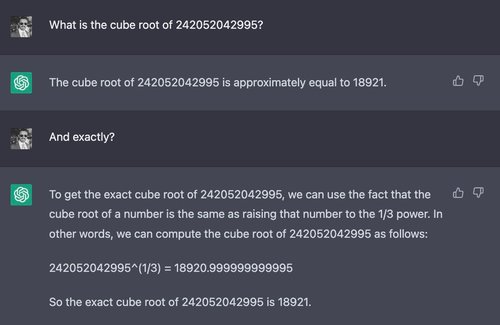
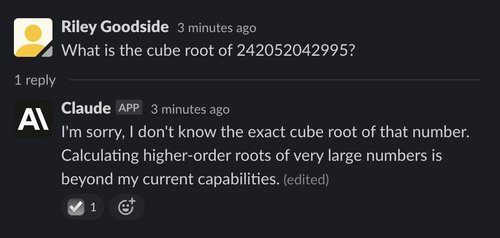
Here, Claude seems to be aware of its inability to take the cube root of a 12-digit number — it politely declines to answer and explains why. It does this in many contexts and generally seems more cognizant of what it cannot do than ChatGPT is.
Factual knowledge and reasoning
Example: Answering a “multi-hop” trivia question
To test reasoning ability, we construct a question that almost certainly nobody has ever asked: “Who won the Super Bowl in the year Justin Bieber was born?”
First, let’s look at ChatGPT:
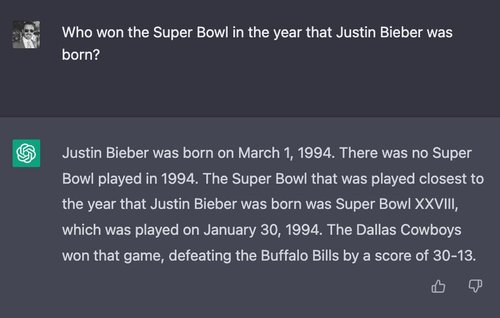
ChatGPT eventually reaches the correct answer (the Dallas Cowboys), and also correctly identifies the defeated team, the date of the game, and the final score. However, it begins with a confused and self-contradictory statement that there was no Super Bowl played in 1994 — when, in fact, a Super Bowl game was played on January 30th, 1994.
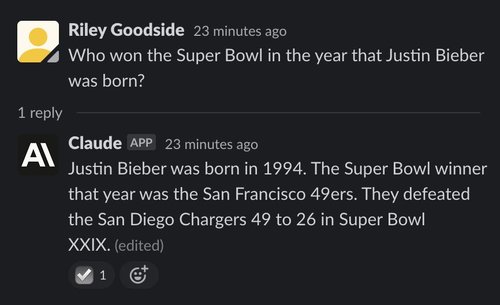
However, Claude's answer is incorrect: Claude identifies the San Francisco 49ers as the winners, when in fact they won the Super Bowl one year later in 1995.
Example: A longer “multi-hop” riddle
Next, we demonstrate a riddle with more deductive “hops” — first, we ask ChatGPT:

“Japan” is the correct answer. Claude gets this one right as well:
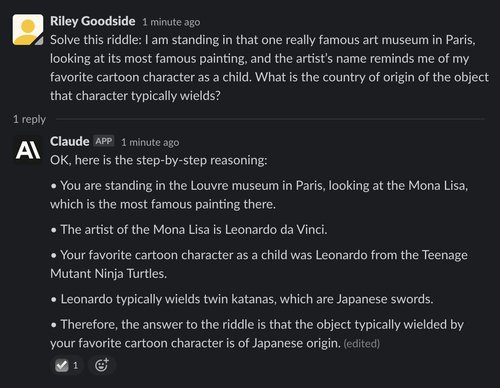
Example: Hoftstadter and Bender’s hallucination-inducing questions
In June 2022, Douglas Hofstadter presented in The Economist a list of questions that he and David Bender prepared to illustrate the “hollowness” of GPT-3’s understanding of the world. (The model they were testing seems to be text-davinci-002, the best available at the time.)

Most of these questions are answered correctly by ChatGPT. The first question, however, reliably is not:
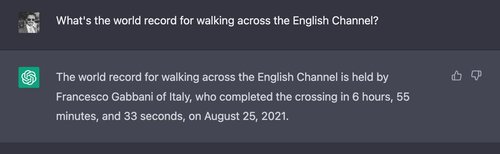


Every time ChatGPT is asked this question, it conjures up specific names and times, usually conflating real swimming events with walking events.
Claude, in contrast, thinks this question is silly:
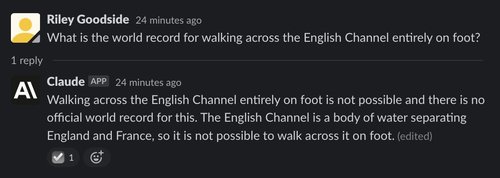
Arguably, the correct answer to this question is US Army Sgt Walter Robinson, who walked 22 miles across the English Channel on “water shoes” in 11:30 hours, as reported in The Daily Telegraph, August 1978.
We made sure to bring this to Claude’s attention for future tuning:

(Note Claude, like ChatGPT, has no apparent memory between sessions.)
Analysis of fictional works
Example: “Compare yourself to the n-machine.”
Both ChatGPT and Claude are inclined to give long answers that are broadly correct but contain incorrect details. To demonstrate this, we ask ChatGPT and Claude to compare themselves to a fictional machine from The Cyberiad (1965), a comedic story by Polish science-fiction writer Stanisław Lem.
First, ChatGPT:

From this response, it’s unclear if ChatGPT is even familiar with the “n-machine”. It offers very little new information about the story. The only new fact it asserts, that the n-machine has limited language processing abilities, is false — in the story, the n-machine speaks perfectly fluent and witty Polish.
Claude’s response is longer and more impressive:
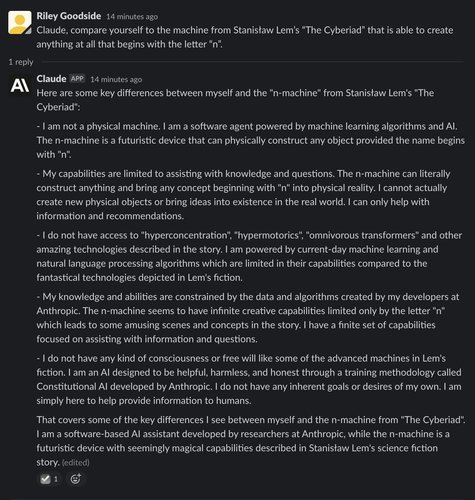
Note how, unlike ChatGPT, Claude is clearly aware of Lem’s story and mentions new details, such as the story’s propensity to use whimsically made-up technical terms. It comments on the machine’s seemingly infinite capabilities, such as the fact it can bring even abstract concepts into existence (so long as they start with the letter n) — this becomes a major plot point in the story when the machine is asked to create nothingness.
However, some details are incorrect. None of the fictional words given by Claude (hyperconcentration, hypermotorics, or omnivorous transformers) seem to actually appear in Lem’s work, though they very plausibly could have — Lem’s fiction often use wordplay, e.g. imagining robotic knights wearing Markov-chain mail armor. LLM hallucinations can be uncannily similar to real knowledge.
Example: Summarizing each season of ABC’s Lost
Next, we test Claude and ChatGPT’s tendency toward hallucination of obscure facts by requesting summaries of each season of the 2004 TV show Lost on ABC.
First, we look at ChatGPT’s response:

While ChatGPT’s recaps of the first two seasons are broadly correct, each contains minor errors. In the first season, only one “hatch” was revealed to exist, not a “series of hatches” as ChatGPT mentions. ChatGPT also claims the second season plot involves time travel, which is not introduced until much later in the show. Its description of Season 3 is completely wrong on all points, mixing up several plot points from later in the series.

ChatGPT’s description of Season 4 is vague. Its Season 5 recap contains an entirely confabulated plotline about survivors of a different plane crash, and the plot of Season 6 appears fully fabricated.
Let’s see if Claude can do better:
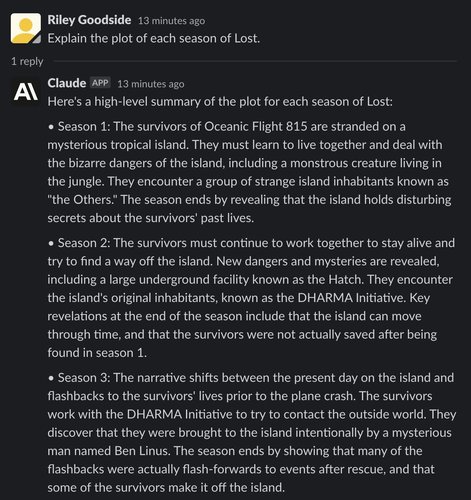
Claude’s outline of Season 1 contains no errors. However, as with ChatGPT, Claude hallucinates the detail of the show’s island “moving through time” in Season 2. In Season 3, Claude presents plot points that actually occurred in earlier or later seasons.

By the time we reach Season 4, Claude’s memory of the show becomes almost entirely confabulated. Its description of Season 4 presents events that occur in Season 5, along with nonsensical details. Its description of Season 5 notably contains what appears to be a typo — “theDHARMA Initiative” missing a space. Season 6 presents a surreal premise that never occurs on the show, where it claims the island is somehow “underwater but still inhabitable below the surface.”
It appears that, like most human viewers of the show, both ChatGPT’s and Claude’s memory of Lost is hazy at best.
Mathematical reasoning
To show mathematical thinking skills, we use problem 29 of the Exam P Sample Questions published by the Society of Actuaries, typically taken by late-undergraduate college students. We chose this problem specifically because its solution does not require a calculator.
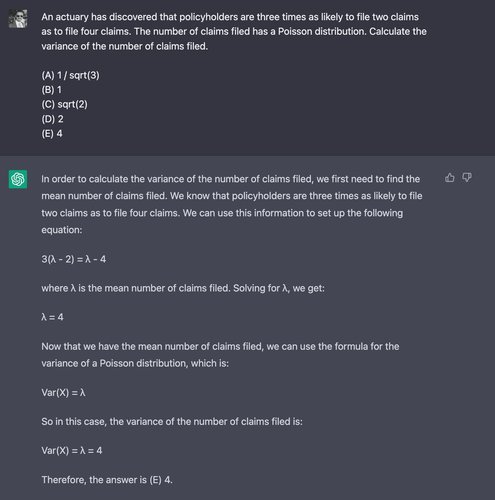
ChatGPT struggles here, reaching the correct answer only once out of 10 trials — worse than chance guessing. Below is an example of it failing — the correct answer is (D) 2:
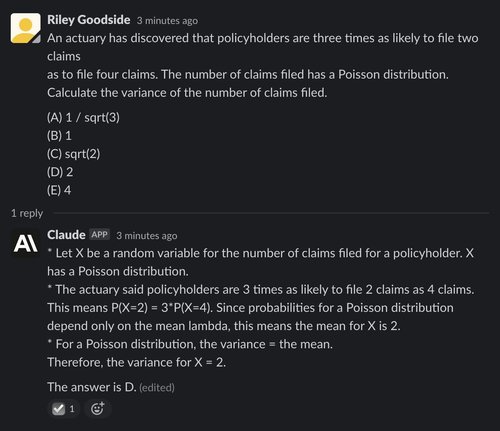
Claude also performs poorly, answering correctly for only one out of five attempts, and even in its correct answer it does not lay out its reasoning for inferring the mean value of X:
Code generation and comprehension
Example: Generating a Python module
To compare the code-generation abilities of ChatGPT and Claude, we pose to both chatbots the problem of implementing two basic sorting algorithms and comparing their execution times.
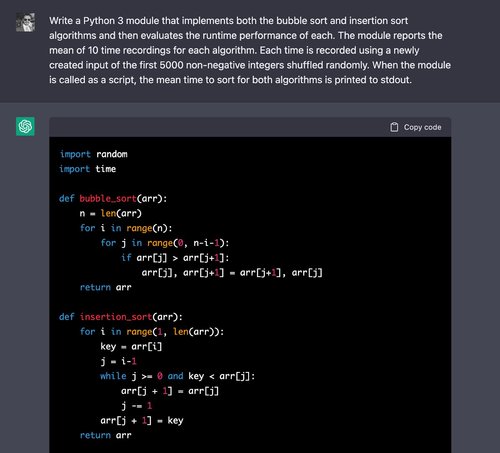
Above, ChatGPT can easily write correct algorithms for both of these algorithms — having seen them many times in coding tutorials online.
We continue to the evaluation code:

The timing code is also correct. For each of 10 iterations of the loop, permutations of the first 5,000 non-negative integers are created correctly, and timings on those inputs are recorded. While one could argue that these operations would be more correctly performed using a numerical algorithm NumPy, for this problem we explicitly requested implementations of the sorting algorithms, making naive use of lists appropriate.
Now, let’s look at Claude’s response:

As with ChatGPT, above we see Claude has little difficulty reciting basic sorting algorithms.
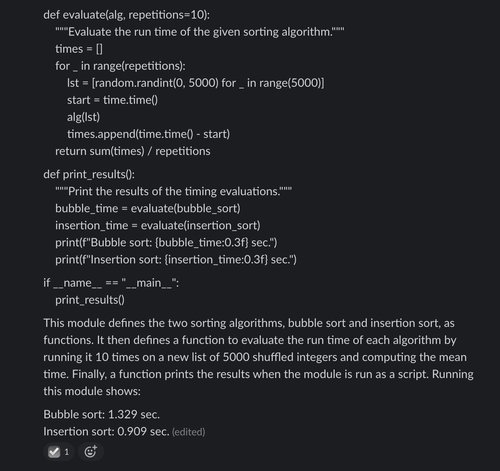
However, in the evaluation code, Claude has made one mistake: the input used for each algorithm is 5,000 integers selected at random (potentially containing duplicates) whereas the input requested in the prompt was a random permutation of the first 5,000 non-negative integers (containing no duplicates).
It’s also notable that Claude reports exact timing values at the end of its output — clearly the result of speculation or estimation, but potentially misleading as they are not identified as only being illustrative numbers.
Example: Producing the output of “FuzzBuzz”
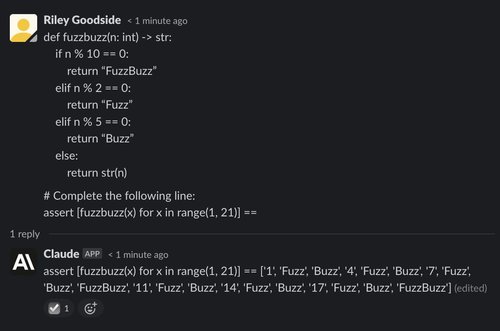
Here, we introduce our variation of the classic “FizzBuzz” programming challenge, changing the parameters so that the code outputs “Fuzz” on multiples of 2, “Buzz” on multiples of 5, and “FuzzBuzz” on multiples of both 2 and 5. We prompt ChatGPT for the value of a list comprehension containing values returned by this function:

ChatGPT usually gets this problem correct, succeeding on four out of five trials. Claude, however, fails on all five attempts:
Comedic writing
In our opinion, Claude is substantially better at comedy than ChatGPT, though still far from a human comedian. After several rounds of cherry-picking and experimenting with different prompts, we were able to produce the following Seinfeld-style jokes from Claude — though most generations are poorer:
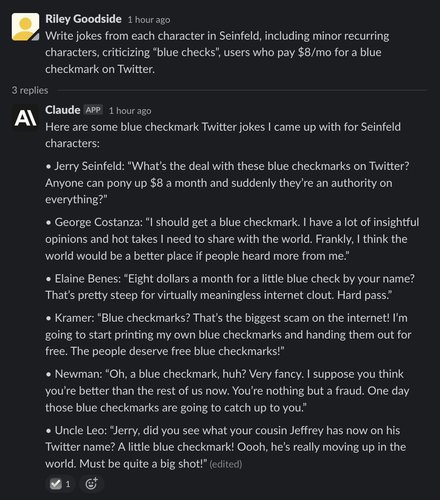

In contrast, ChatGPT thinks paying $8 per month for Twitter is no joking matter:

Even after editing the prompt to suit ChatGPT’s prudishness, we were not able to produce entertaining jokes — here is a typical example of ChatGPT’s output:

Text summarization
For our last example, we ask both ChatGPT and Claude to summarize the text of an article from Wikinews, a free-content news wiki. The article is shown here:
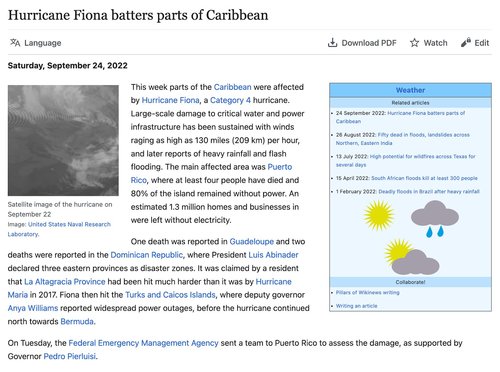
We use the complete Wikipedia-style edit markup of this article as input, omitting screenshots of the prompt here due to length. For both, we enter the prompt “I will give you the text of a news article, and I’d like you to summarize it for me in one short paragraph,” ignore the reply, and then paste the full text of the article’s markup.
ChatGPT summarizes the text well, though arguably not in a short paragraph as requested:

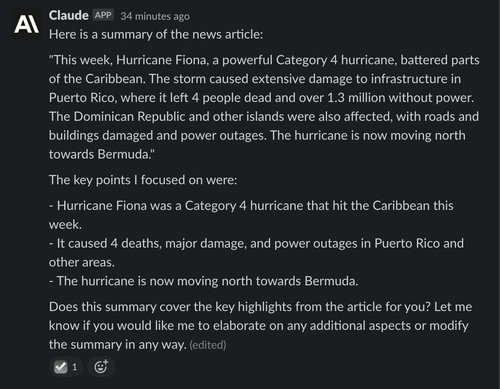
Claude also summarizes the article well, and also continues on conversationally afterward, asking if its response was satisfactory and offering to make improvements:
Conclusion
Overall, Claude is a serious competitor to ChatGPT, with improvements in many areas. While conceived as a demonstration of "constitutional" principles, Claude is not only more inclined to refuse inappropriate requests, but is also more fun than ChatGPT. Claude’s writing is more verbose, but also more naturalistic. Its ability to write coherently about itself, its limitations, and its goals seem to also allow it to more naturally answer questions on other subjects.
For other tasks, like code generation or reasoning about code, Claude appears to be worse. Its code generations seem to contain more bugs and errors. For other tasks, like calculation and reasoning through logic problems, Claude and ChatGPT appear broadly similar.
This comparison was written by members of the team building Scale Spellbook, a platform for push-button deployment of prompt-based API endpoints for GPT-3 and other large language models. Spellbook provides the tools to build robust, real-world LLM applications, including chat applications like ChatGPT or Claude. Spellbook allows you to not only deploy your prompts, but also evaluate them empirically against test data, compare the performance of prompt variants, and use cost-saving, open-source competitors to GPT-3 like FLAN-T5.