Products








Solutions

Retail & eCommerce

Defense

Logistics

Autonomous Vehicles

Robotics

AR/VR

Content & Language

Smart Port Lab

Federal LLMs
Resources
Company
Customers
See all customersVideo





Use Cases
Computer Vision & Classification

Detection & Tracking
Locate and identify objects of various classes and track them frame by frame.
• Product Identification
• Damage and Defect Detection
• Sports Analytics

Prediction & Planning
Understand relationships between objects and predict behavior and intent.
• Autonomous Vehicles and ADAS
• Autonomous Checkout
• Physical Security
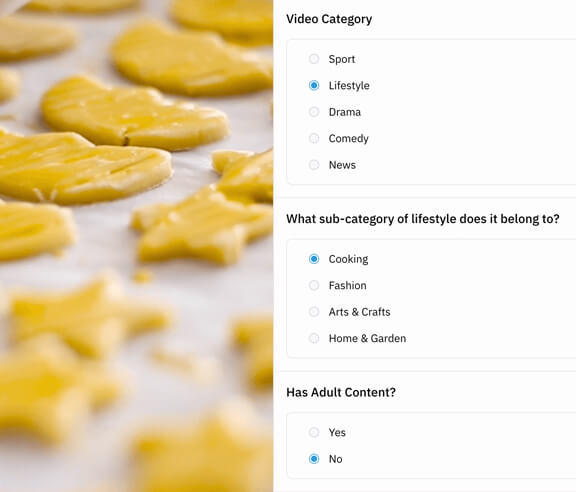
Classification
Classify entire videos or events within videos with start and end timestamps.
• Search and Ad Relevance
• Topic Modeling
• Policy Enforcement
How it works
Easy to Start, Optimize and Scale
Bounding Box
Classification
Polygon
Cuboid
Annotate all the vehicles, pedestrians and traffic lights in the video.


1client.createVideoannotationTask({
2 callback_url: 'http://www.example.com/callback',
3 instruction: 'Annotate all the vehicles, pedestrians and traffic lights in the video.',
4 attachment_type: 'video',
5 attachment: 'http://example.com/video.mp4',
6 objects_to_annotate: ['person'],
7 },
8 (err, task) => {
9 // do something with task
10 }
11);
ML-Powered Data Labeling
Receive large volumes of high-quality annotated videos via ML-powered pre-labeling and active tooling such as smart interpolation and superpixel segmentation as well as ML-based quality checks.

Automated Quality Pipeline
Have confidence in the quality of annotated data. Quality assurance systems monitor and prevent errors. Confidence scores trigger varying levels and types of human review.

Data Input Flexibility
Submit videos as a distinct data type or as a sequence of images for annotation. Native video annotation is best suited for user-generated content, sports footage or any video combined with audio.

Multi-Modal Annotation Support
Jointly represent data to understand relationships between different modalities. Scale supports videos integrated with audio, voiceovers, transcripts, and text in a single task to link different types of data inputs.

Comprehensive Label Support
Specify geometries for different classes (e.g. polygons for furniture, ellipses for plates). Combine geometries in a singular task and label for events (e.g. music playing) to enhance scene understanding.

Infinitely Long Tasks
Annotate hours-long videos to accurately track objects. Our advanced algorithms enable no limits on video length with tracking accuracy even for objects that leave the camera view for long periods of time.
Quality Assurance
Best-In-Class Quality
Super Human Quality
Video tasks submitted to the platform are first pre-labeled by our proprietary ML models, then manually annotated and reviewed by highly trained workers depending on the ML model confidence scores. All tasks receive additional layers of both ML-based checks and human review.
The resulting accuracy is consistently higher than what a human or synthetic labeling approach can achieve independently.

